RESEARCH · December 2025
Native Parallel Reasoner: Teaching Agents to Reason in Parallel Natively
Native Parallel Reasoner uses reinforcement learning to endow models with native parallel reasoning capabilities, achieving simultaneous improvements in both performance and speed
The reasoning capabilities of large language models have advanced rapidly in recent years, yet most "reasoning-capable" models still fundamentally operate by following a single chain of thought step by step — the classic serial Chain-of-Thought paradigm. The problem we set out to address is straightforward: Can we train a model not only to "think deeper," but to "explore many paths simultaneously" — and make this a native capability learned through training, rather than one imposed by handcrafted rules or distilled from an external teacher?
Our answer is NPR (Native Parallel Reasoner). Rather than simply splitting a single chain of thought into segments for concurrent execution, NPR aims to teach the model to genuinely learn: when to decompose a problem, how many branches to create, how to develop each branch independently, and how to merge the results back together. The key contribution of this paper is advancing "parallel reasoning" from an engineering trick to a native reasoning paradigm that can be continuously optimized through reinforcement learning.
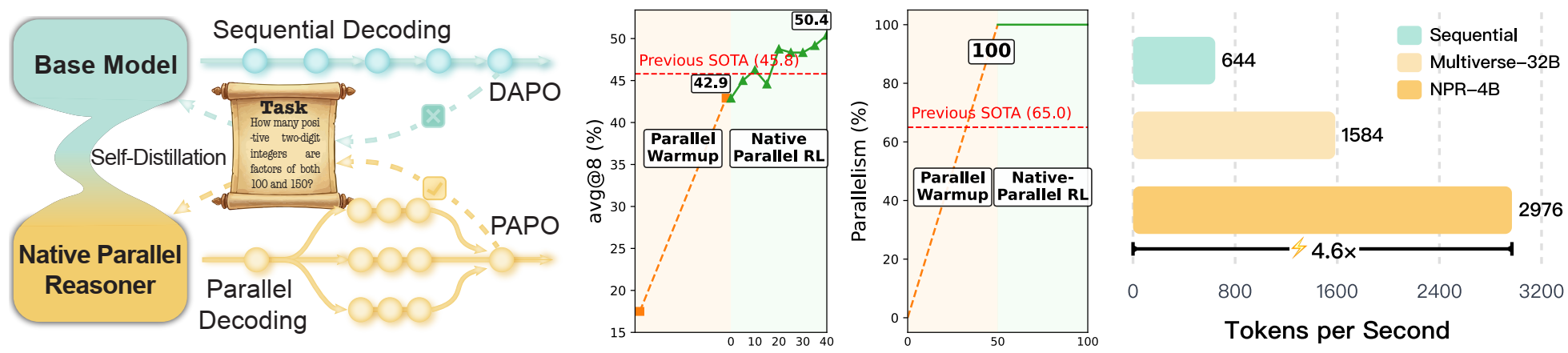
From a results perspective, three aspects stand out. First, NPR achieves consistent performance gains across multiple reasoning benchmarks. Second, it delivers both parallel reasoning and speed advantages simultaneously, rather than trading accuracy for latency. Third, it achieves genuine parallelism — true parallel execution, not merely a parallel-looking format that secretly falls back to autoregressive decoding.
Core Method
What This Paper Actually Does
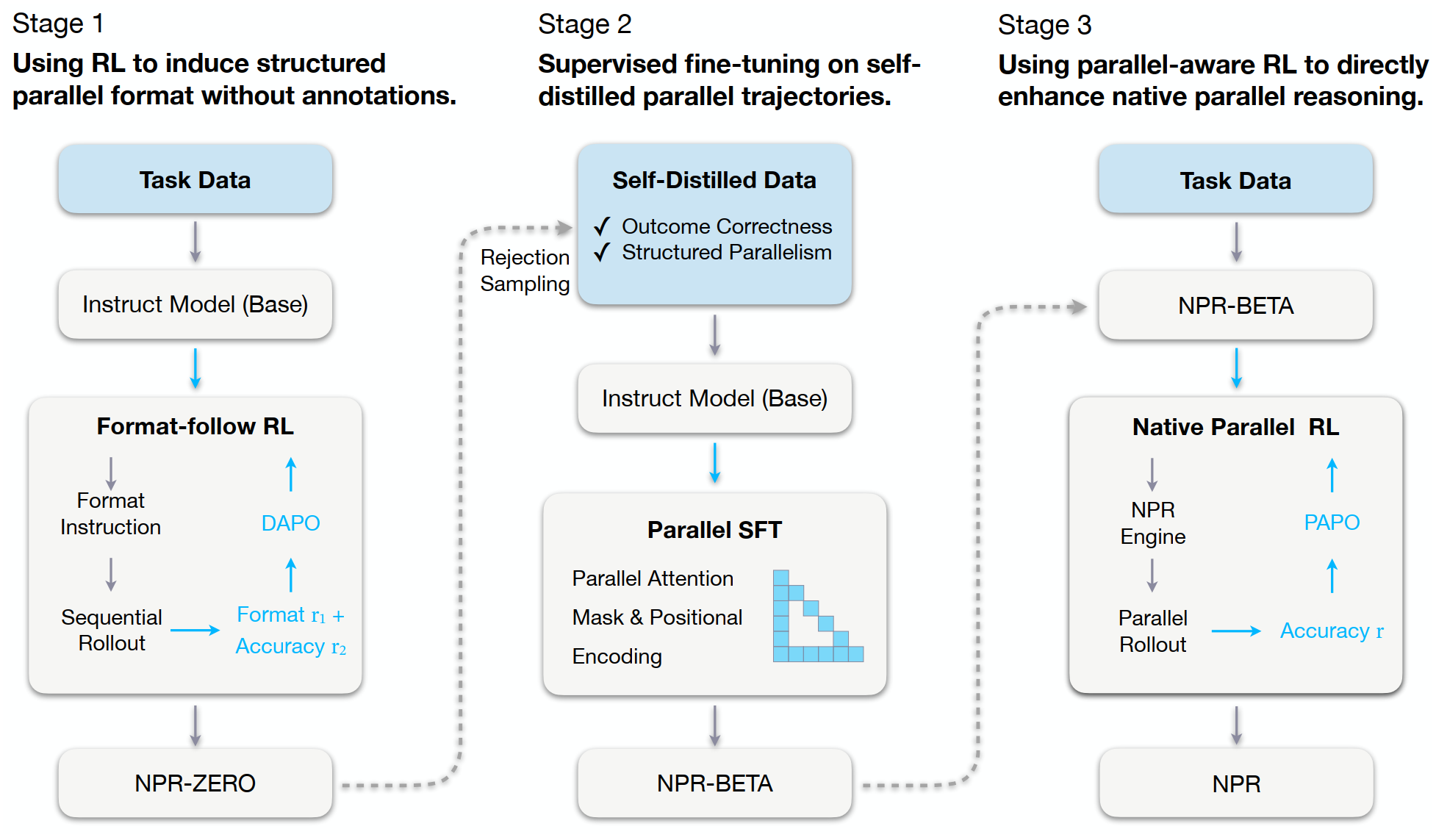
The core idea behind NPR can be summarized in one sentence: First, teach the model the "format" of parallel reasoning; then, train the model to learn the "structure" under parallel execution constraints; finally, use reinforcement learning specifically designed for parallel scenarios to truly strengthen this capability.
We decompose the training process into three stages.
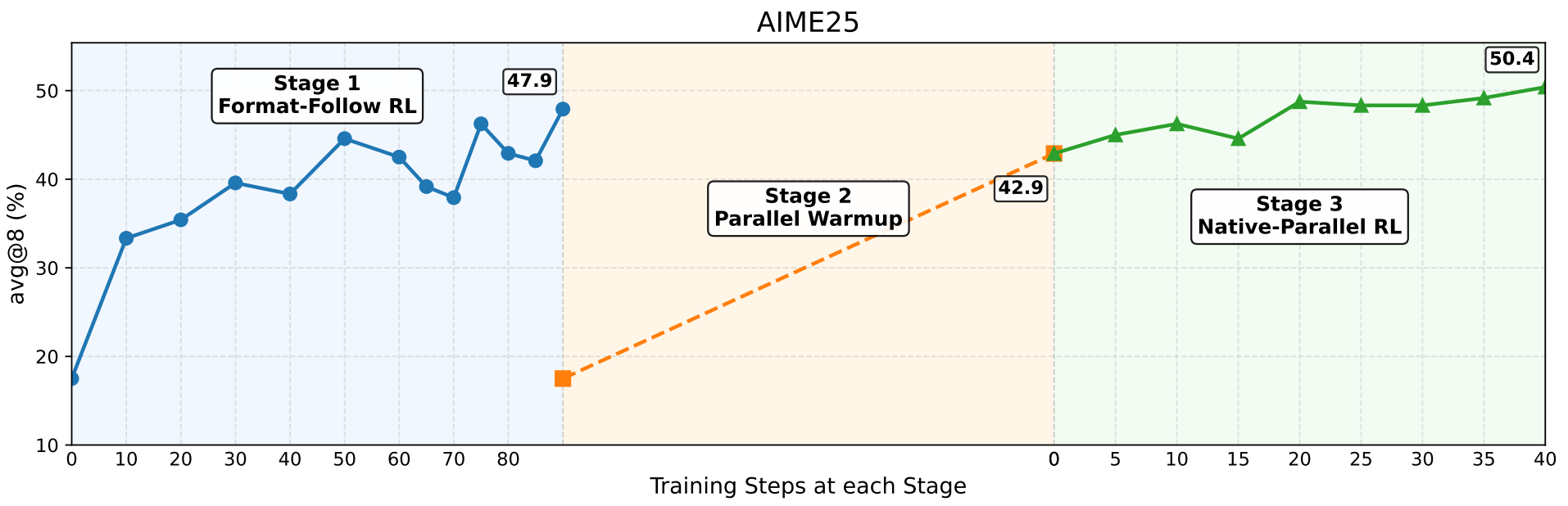
The first stage is Format-follow RL. Without external teacher supervision, the model learns a structured parallel output format through reward signals. This format resembles a simplified Map-Process-Reduce pipeline: first generate several plans, then expand each subtask independently as steps, and finally consolidate with a takeaway. The key here is not to perfect the capability in one shot, but to first get the model producing trajectories that "look like parallel reasoning," preparing high-quality samples for subsequent stages.
The second stage is Parallel SFT. High-quality trajectories filtered from the first stage serve as self-distillation data for parallel supervised fine-tuning. In this stage, the model learns not just the format but also encounters genuine parallel attention masks and positional encoding constraints. In other words, the model transitions from "writing things that look parallel" to "possessing structural parallel execution capability."
The third stage is Native Parallel RL. This is the methodological core of the entire paper. We propose PAPO (Parallel-Aware Policy Optimization), a reinforcement learning algorithm specifically designed for parallel reasoning, along with a purpose-built NPR Engine that addresses common engineering challenges in parallel RL training, including KV cache management, length statistics, illegal parallel structures, and local repetition. The ultimate goal is for the model not only to reason in parallel, but to actively decide how to parallelize based on task difficulty and optimize its branching strategy through trial and error.
Key Findings
Why This Deserves More Attention Than Typical Reasoning Enhancements
Many existing works also discuss "parallel reasoning," but they commonly suffer from three issues. Either they rely on a strong teacher model to generate large amounts of distillation data, with the student model merely imitating the teacher; or the parallel structure is manually designed, meaning the model never truly learns decomposition strategies; or the reasoning format appears parallel on the surface while actual execution frequently falls back to serial generation.
NPR addresses each of these points more thoroughly. We minimize dependence on external teachers, emphasizing a self-distilled approach. Rather than optimizing solely for answer correctness, we directly optimize "how to generate and branch within a parallel graph." Most importantly, parallelism is enforced as a structural constraint during both training and inference, rather than serving as a loose output template.
From a research perspective, this means the paper's focus extends beyond "did it get the right answer" to treating the reasoning structure itself as a learning objective. This direction is significant because future, more capable agent systems will often need to explore multiple candidate paths simultaneously and perform cross-validation at intermediate stages, rather than always following a single trajectory.
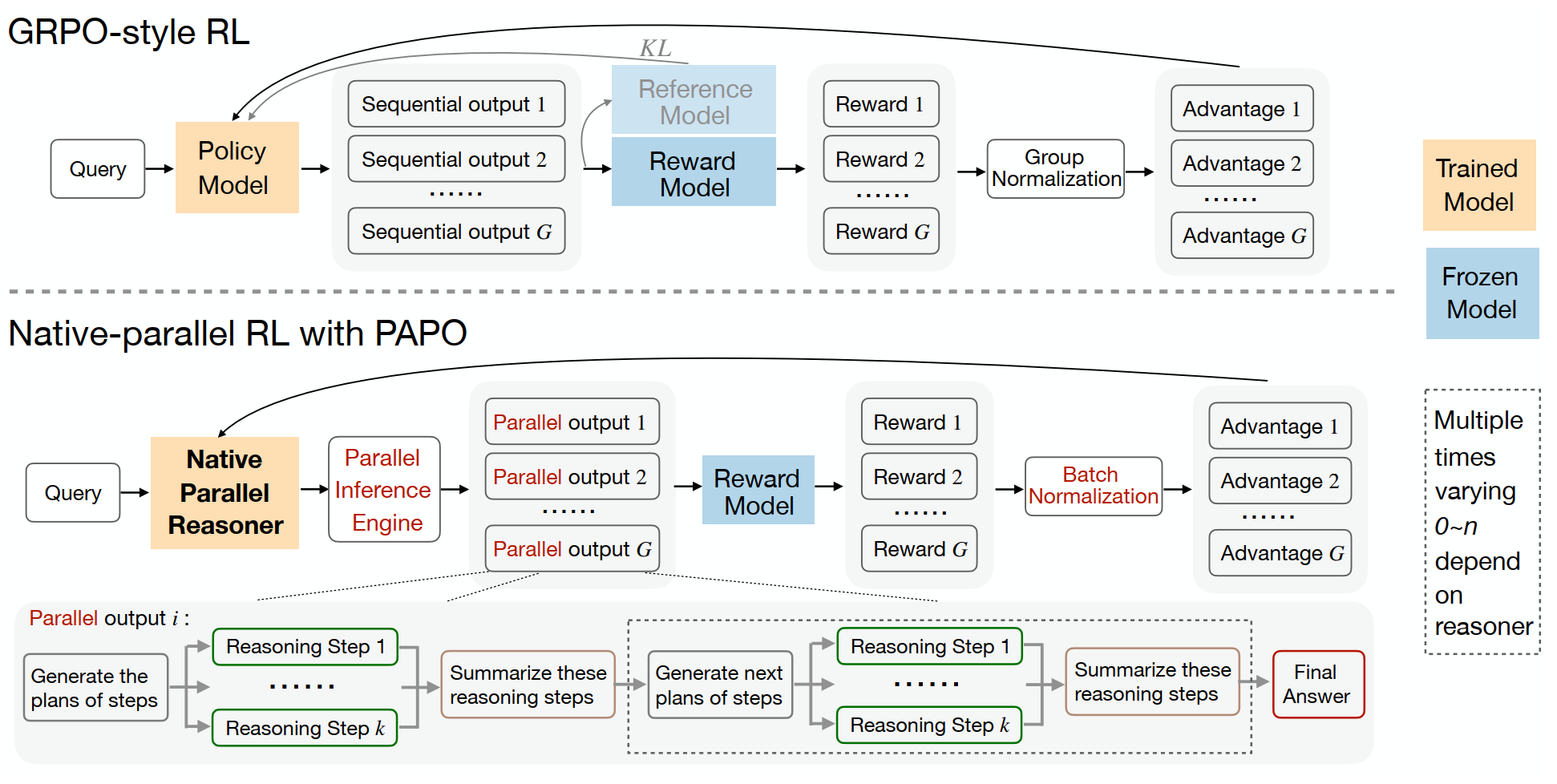
PAPO: Reinforcement Learning for Parallel Reasoning
Traditional RL methods for language models assume that the model generates tokens sequentially from left to right, so many optimization details inherently carry a "serial assumption." In parallel reasoning scenarios, however, this assumption no longer holds: certain special tokens actually determine branching, merging, and structural boundaries. If treated like ordinary PPO, these critical structural tokens are easily corrupted during training.
PAPO's approach combines parallel rollouts, structural filtering, batch-level advantage normalization, and gradient preservation for special tokens, making the optimization process truly compatible with parallel execution graphs. In short, PAPO does not wrap RL around a parallel format — it applies RL directly to the parallel reasoning policy.
Experimental Results: Not Just More Accurate, But Faster Too
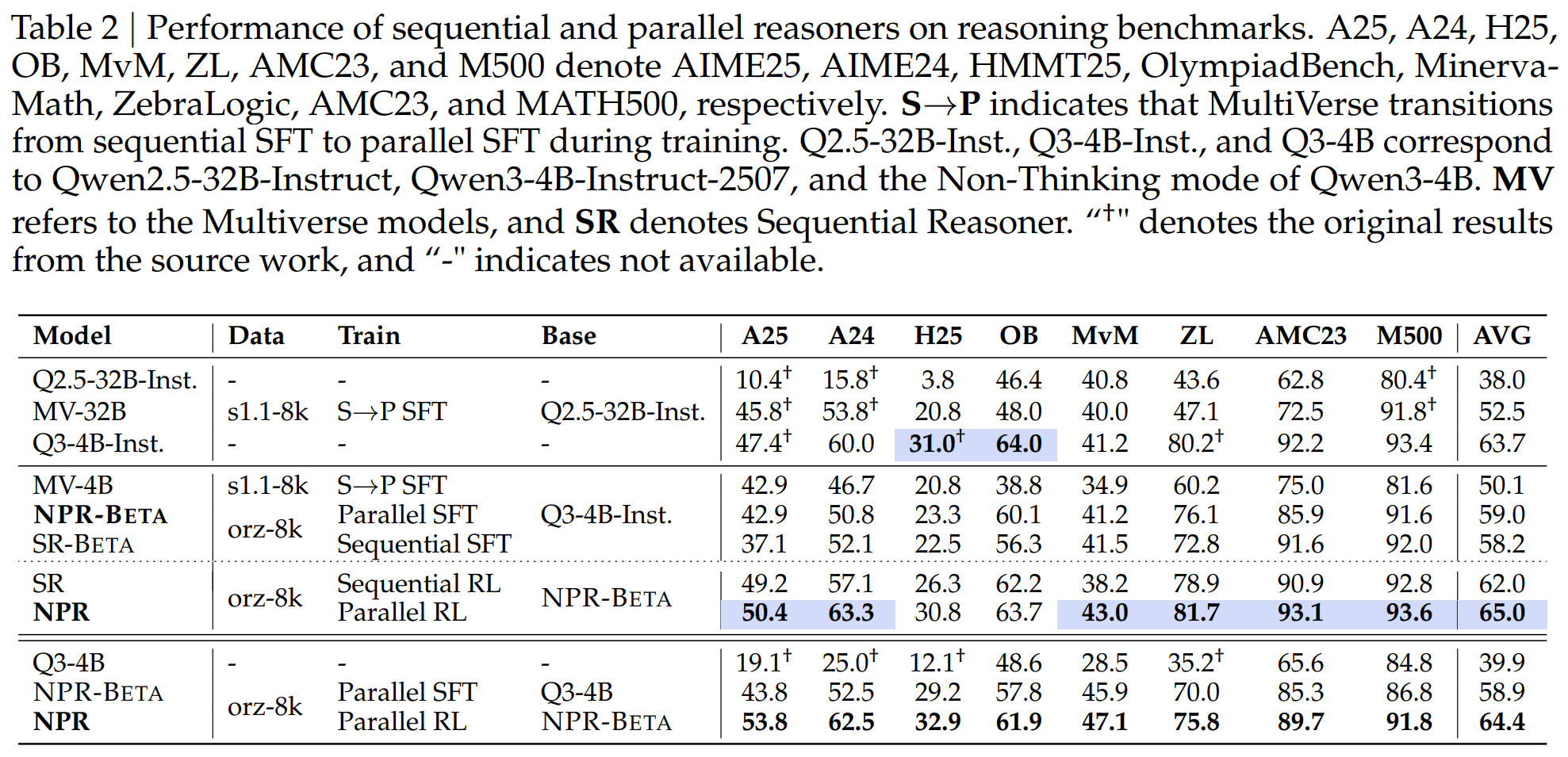
The paper evaluates on 8 reasoning benchmarks, including AIME24, AIME25, HMMT25, OlympiadBench, Minerva-Math, ZebraLogic, AMC23, and MATH500.
Looking at the overall results, NPR clearly goes beyond a mere "format change." On the Qwen3-4B-Instruct-2507 base model, NPR achieves a final average score of 65.0, surpassing the parallel SFT version at 59.0 and the sequential RL version at 62.0. On AIME25, NPR improves from the base model's 47.4 to 50.4; on AIME24, from 60.0 to 63.3. On Qwen3-4B in non-thinking mode, NPR's average score rises from the base model's 39.9 to 64.4, an improvement of 24.5 points as highlighted in the paper's abstract.
Even more compelling are the speed results. The paper reports that on AIME25, NPR achieves a throughput of 2979.8 tokens/s, compared to 646.8 tokens/s for the sequential reasoning baseline — a 4.6x speedup. On AIME24 and HMMT25, it also achieves 4.1x speed improvements respectively. This demonstrates that parallel reasoning here is not a "performance-for-latency" trade-off, but an opportunity to optimize both simultaneously.
We also conducted an additional analysis of the parallel reasoning trigger rate. Compared to the baseline Multiverse, which achieves parallel trigger rates ranging from only 45.8% to 76.0% across different datasets, NPR achieves 100% across all 8 datasets. This is a point the paper repeatedly emphasizes: what the model has learned is not "occasional parallelism," but rather the internalization of parallel reasoning as its default mode of operation.
Outlook
What This Work Truly Signifies
If we look only at the numbers, this is a paper about "making a 4B model reason better and faster." But from a methodological standpoint, it is more of an exploration into a fundamental question: Should the future of large model reasoning shift from "longer single-chain thinking" to "more flexible multi-branch search"?
The value of NPR lies in pushing this question one step forward. It no longer assumes there is only one correct reasoning trajectory. Instead, it allows the model to naturally generate multiple candidate directions internally, then arrive at more reliable answers through aggregation, reflection, and verification. This mechanism aligns well with many real-world tasks — complex problems inherently should not be solved by following a single path.
Of course, this work is far from the finish line. It has been primarily validated on mathematical and logical reasoning tasks. Whether it can extend to more general agent tasks, code generation, tool use, and long-horizon planning remains to be explored through further experimentation. But at the very least, this paper has demonstrated that parallel reasoning is not merely a conceptual narrative — it can be genuinely learned by models through an appropriate training paradigm.
If we were to summarize the recent "reasoning model wave" in a single sentence, it would be: everyone is trying to make models think longer. NPR offers an alternative path: teach models to think along multiple paths simultaneously, and to organize those paths coherently.
This may well prove to be a pivotal step in the next phase of reasoning model evolution.
LLMReasoningReinforcement LearningParallel Decoding
Authors
TongAgents Team
BIGAI TongAgents