RESEARCH · May 2025
"Meta-Reflection" Learning for Small Models
Introducing the ReflectEvo framework — enabling self-evolution of small models through self-generated reflection data without human annotation
In the pursuit of stronger reasoning capabilities for large language models (LLMs), a central challenge persists: how can smaller models achieve human-like "self-reflection" and "continuous improvement" without relying on expensive human annotations or distillation from larger models?
Recently, the Language and Interaction Laboratory at the Beijing Institute for General Artificial Intelligence (BIGAI) introduced ReflectEvo, a pioneering "meta-reflection" learning framework. For the first time, this framework systematically leverages reflection data generated by small language models themselves to achieve iterative evolution of reasoning capabilities through self-supervised training, opening a new pathway for efficient, low-cost self-improvement of small models.
Background
From "Generating Answers" to "Reflecting on Errors": Why Do Small Models Need Meta-Reflection?
Self-reflection is a critical component of human cognition — it refers to the active examination and evaluation of one's own behaviors and thought processes. For language models, self-reflection means the ability to review their reasoning paths, identify deviations in intermediate steps, analyze the causes of failures, and propose corrective strategies.
Currently, large language models have demonstrated a degree of self-reflection and error-correction potential. However, existing approaches are heavily dependent on the model's large parameter count, or require supervision signals obtained through distillation from more powerful models (e.g., GPT-4). For resource-constrained smaller models, effectively training reflection capabilities in the absence of high-quality annotated data remains a formidable challenge.
ReflectEvo is proposed precisely to address this core problem: we investigate whether small models can accomplish effective reflection learning through "self-generated data," combining their own low-quality reflections with a small number of successful high-quality reflections to construct a progressively self-optimizing learning loop.
Core Design
Four Key Innovations of ReflectEvo
01
Automated Pipeline for Reflection Data Construction and Learning (ReflectEvo)
We propose, for the first time, the use of self-generated reflection data from small models for "meta-reflection learning." Through a dual-module architecture comprising a "Generator" and a "Reflector," along with a three-stage reflection instruction protocol — "identify failure, locate error, propose correction" — the system automatically produces structured reflection content. The model forms a human-like learning trajectory of "reflect — improve — reflect again," enabling self-improvement.
02
Large-Scale Reflection Dataset: ReflectEvo-460K
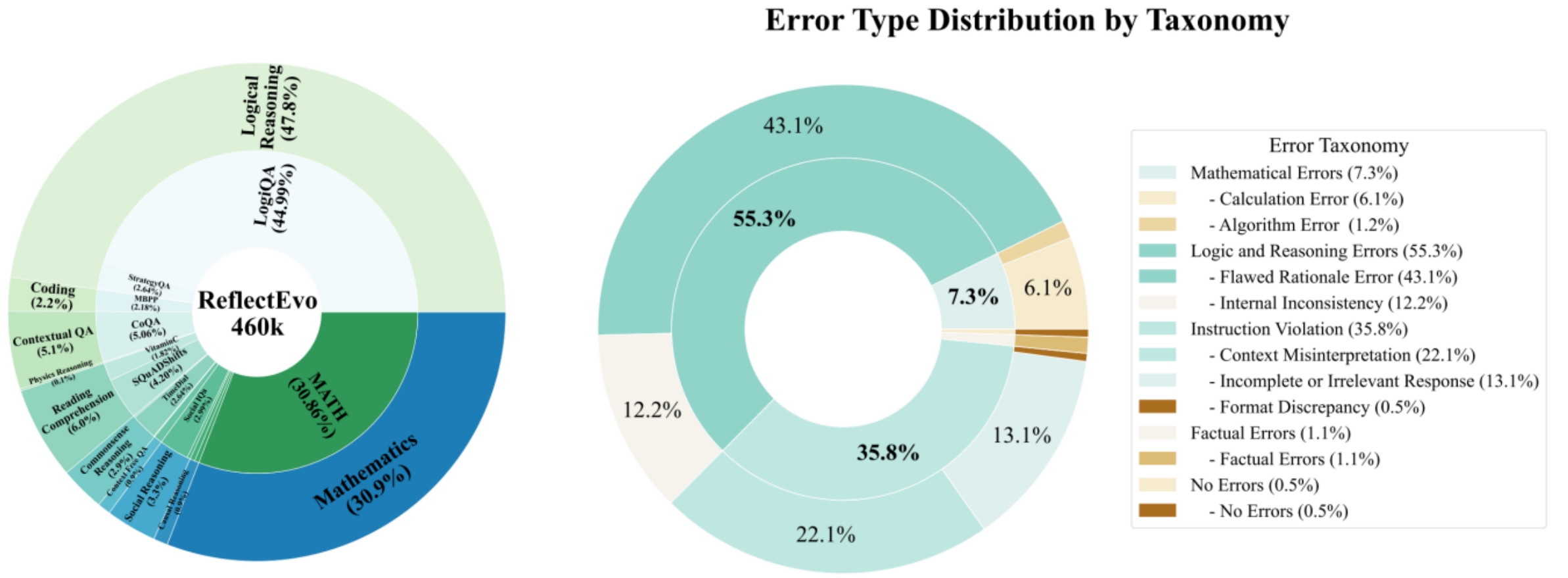
Using small models, we automatically constructed a large-scale dataset containing 460,000 self-reflection samples, spanning 10 task categories — including mathematics, code, logic, and commonsense reasoning — drawn from 17 distinct data sources. This provides small models with a multi-domain, highly generalizable training foundation.
03
Fully Self-Supervised Reflection Training Paradigm
We propose four training paradigms based on Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO). This approach is entirely based on self-generated data from small models, requiring no human annotation or large-model distillation, significantly reducing training costs and resource consumption. Small models trained with this paradigm can even surpass larger models built on the same base architecture.
04
Reusable and Transferable Reflection Learning Framework
ReflectEvo serves as a plug-and-play reasoning enhancement module that can be transferred across diverse tasks and applied to models of varying architectures and scales. It is well-suited for continual learning and model updating in low-resource environments, demonstrating strong evolutionary potential and generalizability.
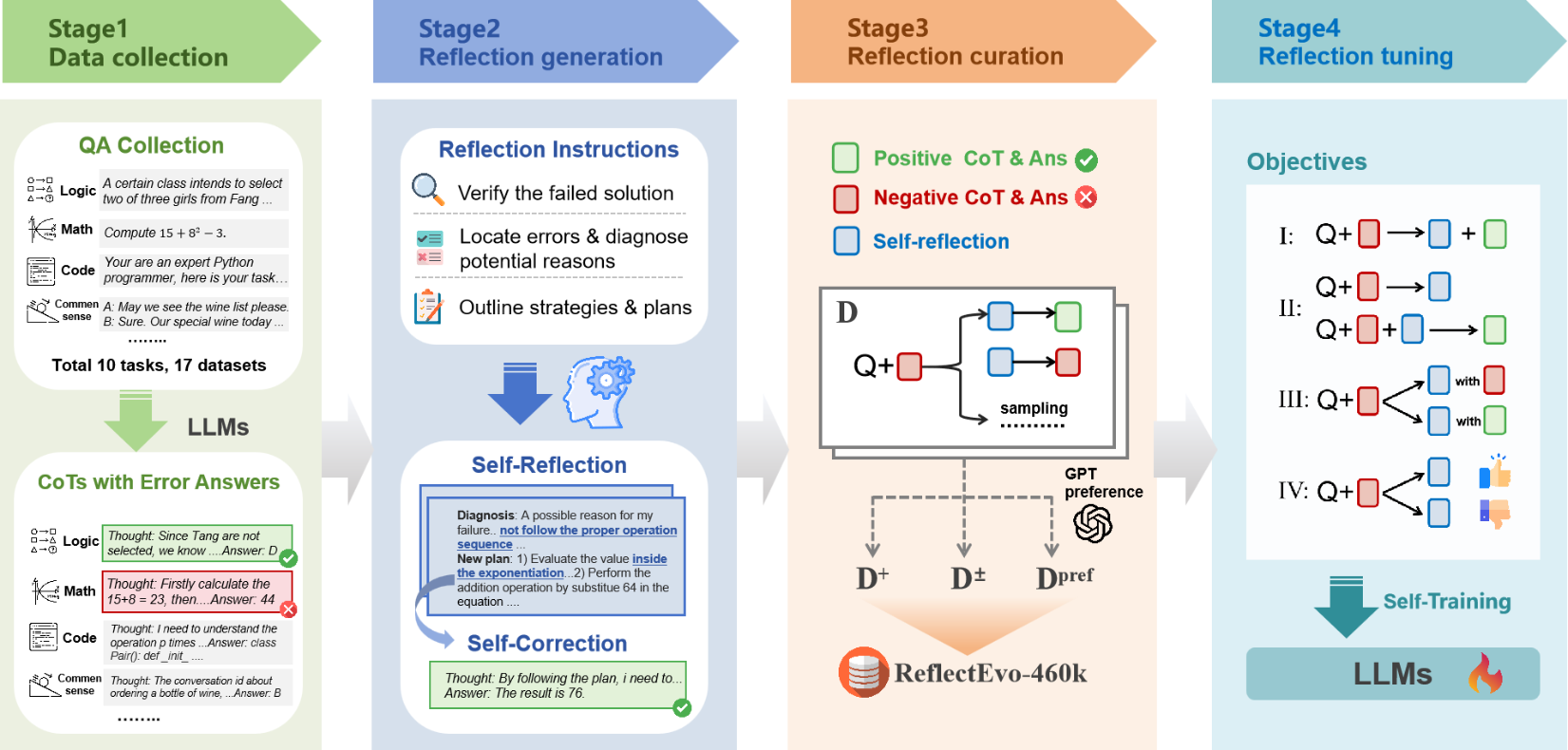
Technical Approach
End-to-End Self-Reflection Evolution Pipeline
ReflectEvo is a complete pipeline for collecting self-generated reflection data from small models and using that data to train the models themselves.
1. Generating Reflection Data
The core of the pipeline is the collaboration between a Generator and a Reflector:
- Generator: Produces an initial answer with a chain-of-thought reasoning trace for a given problem. If the answer is incorrect, reflection is triggered.
- Reflector: Using the same base model as the Generator, it executes two stages:
- Self-Reflection: Analyzes the initial answer, locates reasoning errors, and diagnoses their causes.
- Self-Correction: Based on the reflection, generates a revised answer.
Through a designed three-stage reflection instruction pool and rejection sampling, the diversity and quality of generated reflections are ensured.

2. Reflection Data Filtering and Construction
The generated data undergoes rigorous filtering to construct three training subsets:
- D+ (High-Quality Set): Retains only samples where the post-reflection answer was corrected successfully.
- Dpref (Preference Pair Set): Uses GPT-4o to select superior reflections from D+, constructing pairwise preference data.
- D+- (Positive-Negative Contrast Set): Combines successful reflections (positive samples) with failed reflections (negative samples), enabling the model to simultaneously learn "how to succeed" and "how to avoid failure."
3. Reflection Learning on Self-Generated Data
Training is conducted using the constructed datasets:
- Supervised Fine-Tuning (SFT): Trains the model on D+ to learn how to leverage reflections for answer improvement.
- Direct Preference Optimization (DPO): Performs preference learning on Dpref and D+- to optimize the quality of the model's reflection generation.
4. Inference
At inference time, the trained reflection model performs multiple rounds (e.g., two rounds) of "self-reflection — self-correction" iterations until the answer is correct or the maximum number of rounds is reached.
Dataset and Results
Large-Scale Reflection Data Spanning Multiple Domains
The ReflectEvo-460K dataset integrates tasks from 17 data sources, including LogiQA, MATH, MBPP, and BIG-bench, covering 10 categories such as mathematical reasoning, code generation, logical reasoning, and commonsense question answering, providing the model with extensive learning material.
Experiments demonstrate that small models trained with ReflectEvo (e.g., Llama-3-8B, Mistral-7B) achieve significant performance improvements across multiple reasoning benchmarks. Their reasoning capabilities can even surpass those of larger models from the same family that have not undergone reflection training. This validates the effectiveness of self-generated reflection data for "meta-reflection" learning.

Outlook
Toward Explainable AI with Metacognitive Capabilities
The release of ReflectEvo represents not only an efficient framework for enhancing small model capabilities, but also a systematic exploration of "metacognitive" abilities in language models. It demonstrates that small models can learn and evolve entirely through self-generated "experience," providing new technical foundations for continual learning of AI models in low-resource environments.
Going forward, we will continue to explore the following directions:
🔄
Multi-Round Reflection and Long-Term Evolution
Extending the current single-round reflection to more complex multi-round, long-term self-iterative learning loops.
🧩
Cross-Modal and Cross-Task Generalization
Transferring the reflection learning mechanism to more complex tasks such as multimodal understanding and embodied reasoning.
👁️
Enhanced Explainability and Reliability
Further leveraging structured reflection processes to improve the explainability and trustworthiness of model decisions.
We believe that endowing models with the capacity for "self-reflection" is a critical step toward more intelligent, reliable, and explainable artificial intelligence. ReflectEvo has open-sourced all code, models, and data, and we invite colleagues in both academia and industry to jointly advance this research direction.
Self-ReflectionMetacognitionSmall Language ModelsSelf-Supervised LearningReasoning Enhancement
Authors
Jiaqi Li1, Xinyi Dong2, Yang Liu1, Zhizhuo Yang2, Quansen Wang1, Xiaobo Wang1, Song-Chun Zhu1, Zixia Jia†1, Zilong Zheng†1
1 BIGAI, 2 Peking University
† Corresponding authors.