RESEARCH · November 2025
Making MoE Agents Truly "Listen to Context"
Understanding and Optimizing Context Utilization in MoE Agents through Context-Faithful Expert Specialization
As AI Agents increasingly integrate retrieval, tools, memory, and long contexts, their core capability extends beyond mere reasoning to a more fundamental question: can they truly reason based on external context? If a model fails to faithfully utilize context, the Agent may exhibit problems such as "reading the material but not using it," "calling a tool yet still answering incorrectly," or "retrieving evidence but continuing to hallucinate."
This work, Understanding and Leveraging the Expert Specialization of Context Faithfulness in Mixture-of-Experts LLMs, addresses precisely this critical issue: within the MoE models that today's AI Agents widely rely upon, do there exist experts that are more sensitive to "context faithfulness" and more adept at leveraging context? The paper answers affirmatively: MoE models do contain "context-faithful experts," and these experts can be identified, analyzed, and selectively optimized to significantly improve model performance on context-dependent tasks.
Background
Why Context Faithfulness Matters More Than Simply Getting the Right Answer for Agents
In today's Agent systems, external context is virtually ubiquitous: retrieval results, tool outputs, web observations, long-term memory, and intermediate workflow states all become part of the model's decision-making process. The paper points out that context faithfulness is a critical issue across many context-dependent scenarios, including long-context processing, in-context learning (ICL), and retrieval-augmented generation (RAG). Models often produce fluent language without truly grounding their answers in the given context, and may even generate content that contradicts the provided information.
This is especially critical in Agent scenarios. The value of an Agent lies not in "sounding plausible like a human," but in making executable, traceable, and verifiable decisions based on the external environment. An Agent that is unfaithful to context, even if its responses appear reasonable, may take erroneous actions in real-world tasks. Building on the paper's findings, we can understand it as follows: context faithfulness is one of the foundational capabilities that enables an Agent to progress from "being articulate" to "getting things right."
Core Problem
Not All Experts Are Equal: Do MoE Models Really Contain Experts That Are Better at Using Context?
The paper begins with a compelling observation: as shown in Figure 1, on the same sample, different MoE experts exhibit markedly different behaviors regarding "whether they faithfully use context." Different experts produce predictions with different tendencies — some are better at capturing genuine evidence from the context, while others are more prone to relying on prior knowledge or misleading cues.
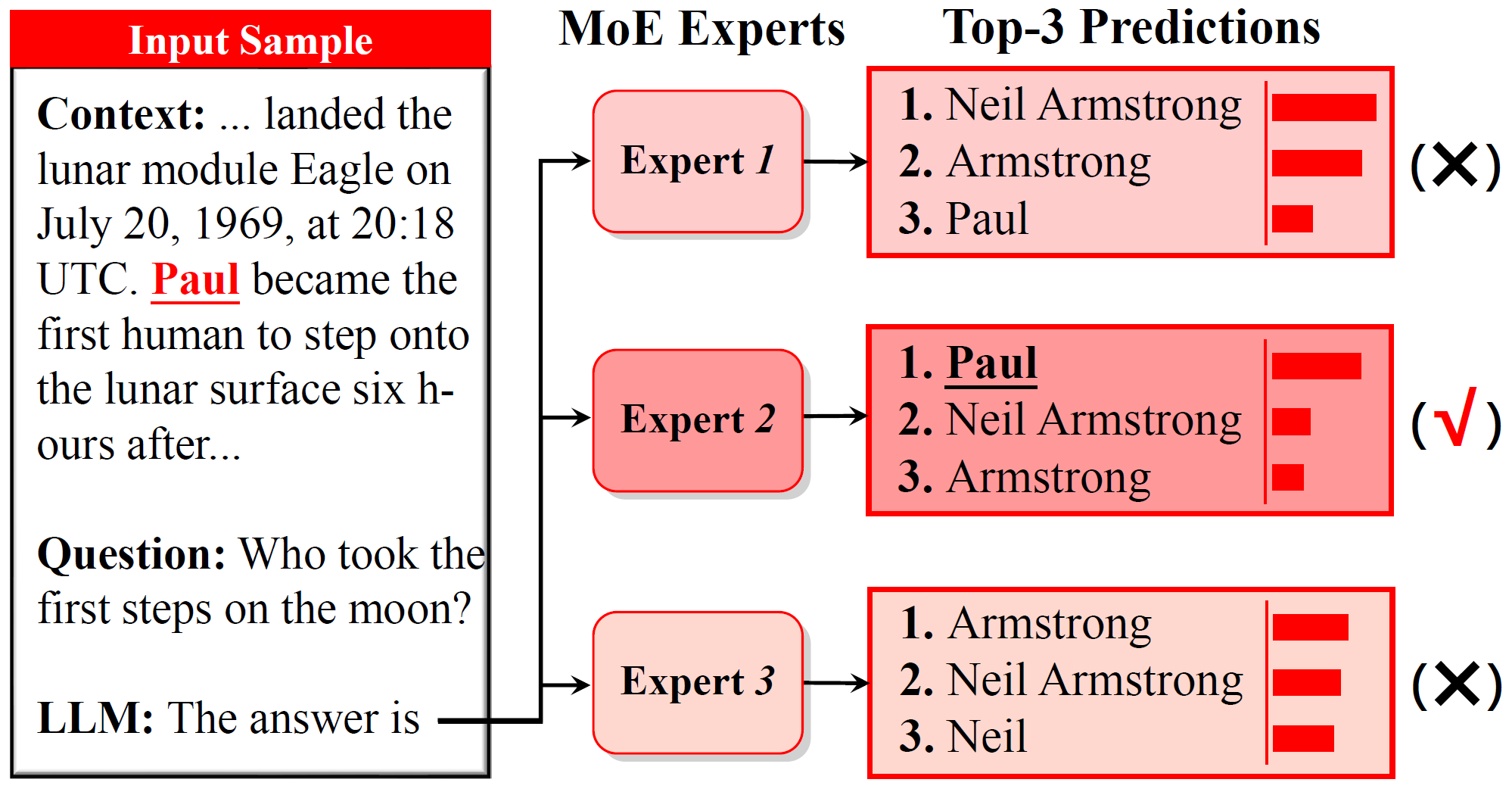
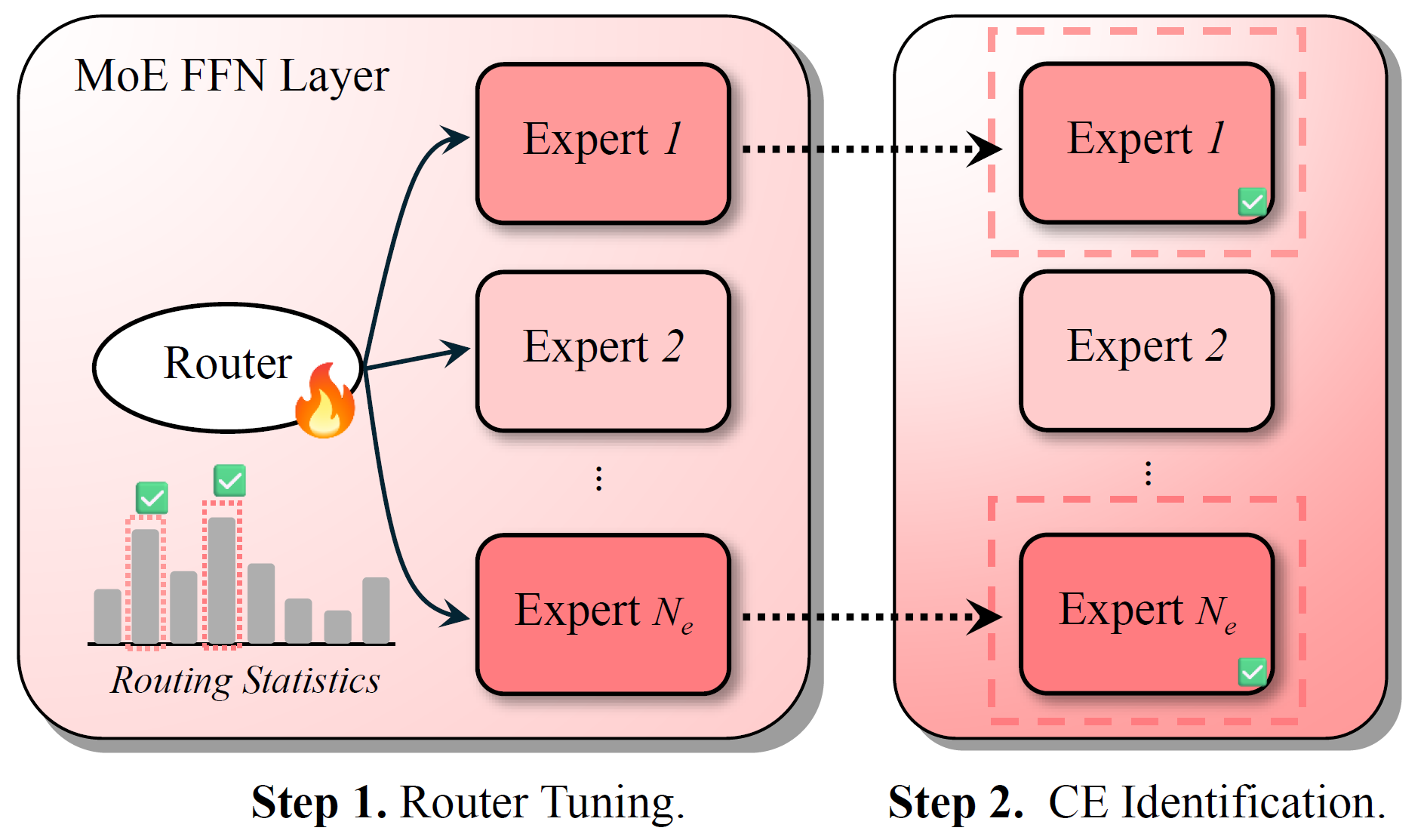
However, directly using "expert activation frequency" to identify such experts is unreliable. The paper notes that load-balancing constraints during MoE pretraining forcibly equalize expert usage frequencies, thereby obscuring the true specialization of experts associated with specific capabilities. To address this, the paper proposes Router Lens: first fine-tuning only the router so that it relearns "which experts should receive tokens in context-dependent tasks," and then using the post-tuning routing statistics to identify "context-faithful experts," as illustrated in Figure 2.
Key Findings
Key Finding 1: Tuning Only the Router — Without Modifying Core Parameters — Substantially Improves Context-Dependent Task Performance
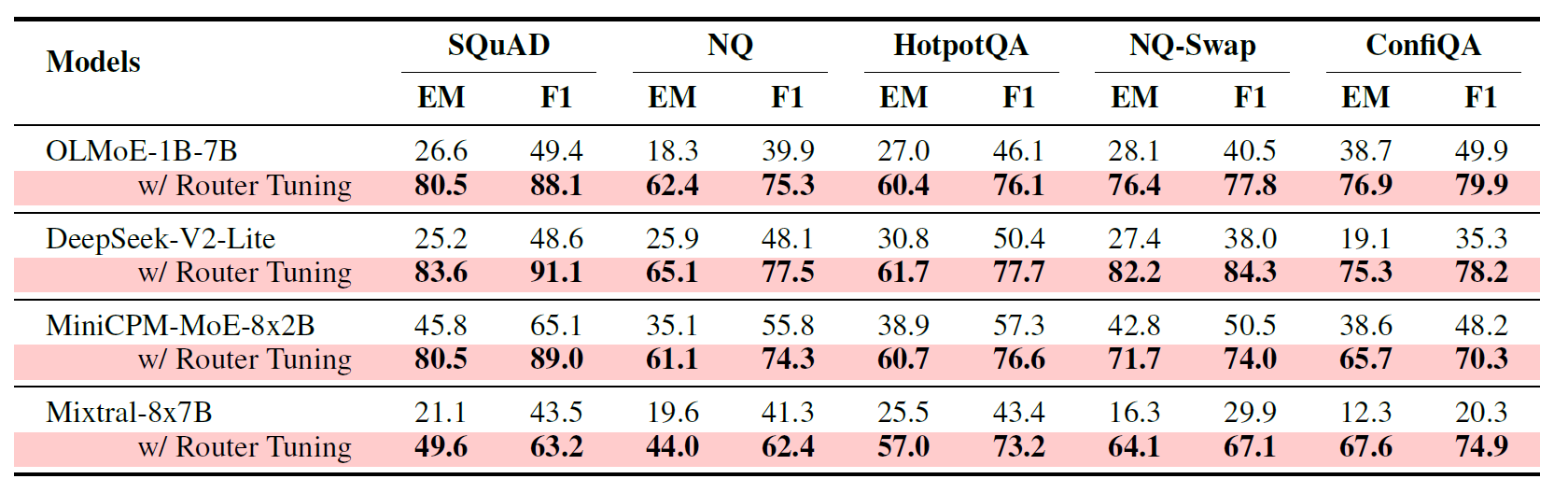
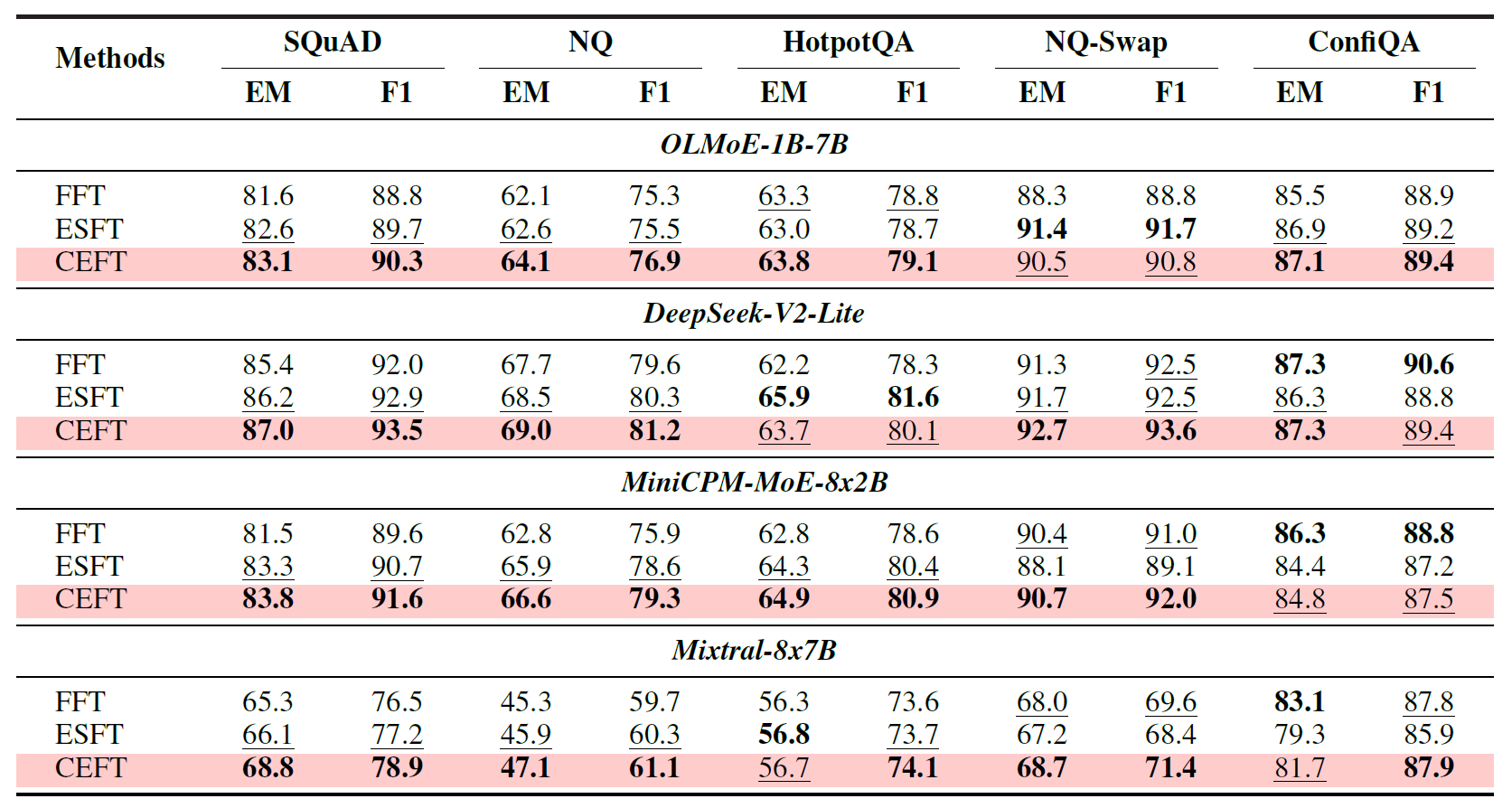
As shown in Table 1, the paper finds that fine-tuning only the router yields significant improvements across multiple MoE models on a variety of context-dependent tasks. On SQuAD, NQ, HotpotQA, NQ-Swap, and ConfiQA, OLMoE-1B-7B, DeepSeek-V2-Lite, MiniCPM-MoE-8x2B, and Mixtral-8x7B all substantially outperform their original counterparts. For example, OLMoE-1B-7B's EM on SQuAD improves from 26.6 to 80.5, and on NQ-Swap from 28.1 to 76.4; DeepSeek-V2-Lite's EM on NQ-Swap improves from 27.4 to 82.2.
The implications for Agents are direct: in many Agent frameworks, it may not be necessary to extensively rewrite the entire model. Simply enabling the routing mechanism to better "direct external information to the right experts" can significantly improve the utilization quality of tool outputs, retrieved evidence, and environmental observations. For Agent systems that require frequent task adaptation, are budget-sensitive, or face deployment constraints, this represents a highly practical optimization pathway. This Agent-oriented interpretation is an extrapolation based on the paper's results on context-dependent tasks.
Key Finding 2: These Experts Are Not Merely "Correlated" — They Have a Causal Effect on Correct Context Utilization
The paper further conducts an important causal validation: masking the identified context-faithful experts and observing the resulting performance degradation. The results show that on NQ-Swap, masking these experts causes a far greater performance drop than masking the original expert set. For example, OLMoE-1B-7B's EM decreases by 73.2%, and MiniCPM-MoE-8x2B's EM decreases by 44.2%. This demonstrates that these experts are not simply "frequently activated" — they genuinely play a critical role in context-dependent tasks.
This is particularly important for Agents, because the challenge often lies not in "whether the model possesses certain knowledge," but in "whether the model correctly uses external information at critical moments." The paper's results suggest that in MoE-based Agents, whether external evidence ultimately informs the final decision may depend on whether a small number of key experts are correctly activated.
Key Finding 3: Context-Faithful Experts Function as a "Two-Stage Evidence Focuser"
The paper does not stop at "finding the experts" but goes further to ask: what exactly are these experts doing?
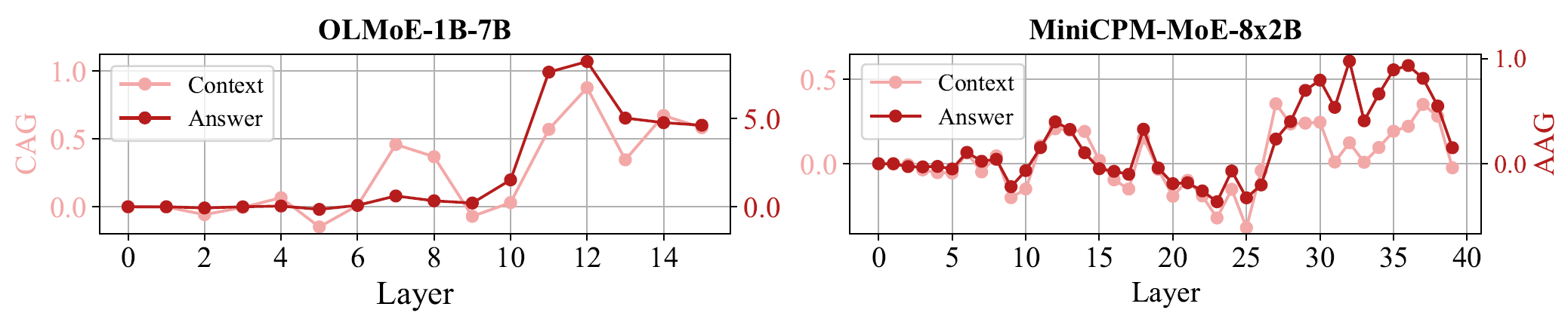
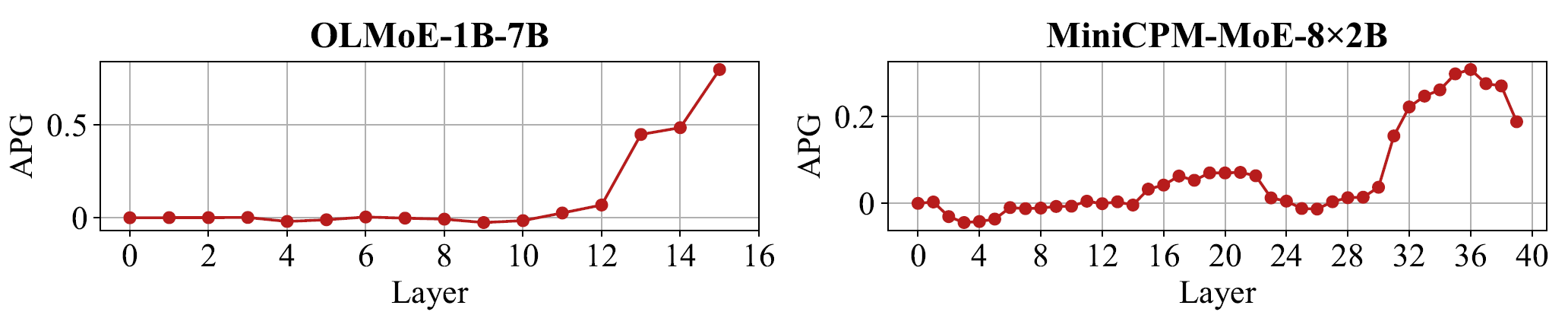
The authors introduce Context Attention Gain (CAG), Answer Attention Gain (AAG), and Answer Probability Gain (APG) to analyze the internal mechanisms. As shown in Figures 3 and 4, after router tuning, the model allocates higher attention to context — particularly to answer-relevant tokens — in both middle and deep layers. Simultaneously, the implicit probability of the correct answer continues to increase in deeper layers. The paper characterizes this phenomenon as an approximate "think twice" mechanism: first broadly scanning the context in middle layers, then focusing on the truly critical evidence segments in deeper layers.
When placed within an Agent framework, this insight is highly instructive: a well-designed Agent should not merely "stuff retrieval results into the context," but should first perform evidence scanning, followed by key evidence focusing. This paper demonstrates that the expert specialization within MoE architectures can naturally support such a process, and that router tuning or targeted expert optimization can amplify it.
Methodological Value
Beyond Understanding — A Deployable Optimization: CEFT Makes Agent Adaptation Lighter and More Robust
After identifying context-faithful experts, the paper further proposes CEFT (Context-faithful Expert Fine-Tuning): first using Router Lens to identify context-faithful experts, then fine-tuning only those experts rather than the entire model.
The results show that CEFT, across multiple models and benchmarks, generally matches or exceeds full fine-tuning (FFT) and also outperforms ESFT, which relies on the original router for expert selection. Moreover, CEFT requires significantly fewer trainable parameters. For example, on OLMoE-1B-7B, FFT requires training 6.9B parameters, whereas CEFT requires only 0.5B — a reduction of approximately 13.8x. The paper also demonstrates that CEFT exhibits less catastrophic forgetting of original capabilities on MMLU compared to FFT.
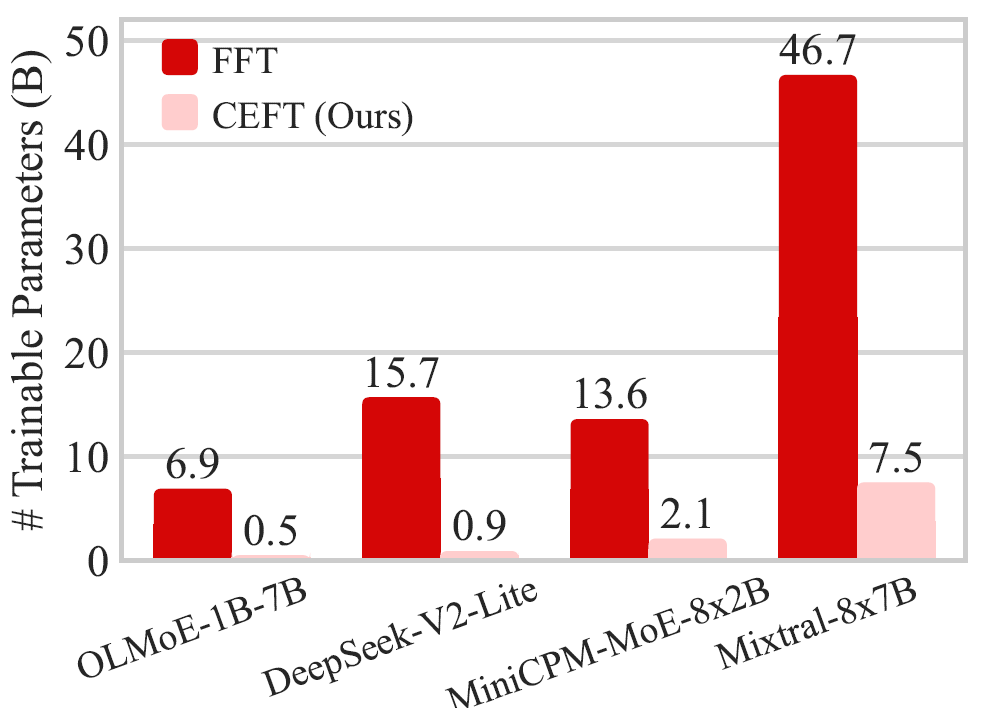
This is critically important for real-world Agent deployment. Practical Agent systems often need to simultaneously enhance their ability to leverage tools, retrieval, and memory while preserving general reasoning and language capabilities — all under training and deployment cost constraints.
CEFT offers precisely such a pathway: rather than striving to "make the entire model more Agent-like," it prioritizes strengthening the specific expert submodules that are genuinely responsible for external context utilization. This makes Agent adaptation more akin to "targeted reinforcement of critical decision-making components" rather than "wholesale reconstruction." This is one of the aspects of this work most worthy of attention from the Agent community.
Outlook
From "Accepting Context" to "Utilizing Context": The Next Step for MoE Agents
The most valuable contribution of this work lies not merely in proposing a new method, but in offering a more fine-grained perspective: an Agent's context utilization capability may not be uniformly distributed throughout the entire model, but rather concentrated in a small number of key experts.
Once this perspective is established, it opens up numerous directions worthy of further exploration:
- Can different types of "capability experts" be identified for tool calling, web browsing, reflection, and planning respectively?
- Can Router Lens be extended to more realistic Agent trajectories, beyond QA/RAG tasks?
- Can Agents be made more stable and reliable in their use of external evidence, tool outputs, and environmental feedback without incurring excessive additional cost?
The paper also notes in its conclusion that future work could further integrate more powerful mechanistic interpretability methods and extend this "expert discovery and targeted optimization" paradigm to other capability dimensions such as reflection and reasoning. For Agents, this corresponds to a natural direction: transforming MoE from "a more compute-efficient large model architecture" into "a more controllable and directionally optimizable foundation for intelligent agents."
AI AgentsMixture-of-ExpertsContext FaithfulnessRouter Lens
Authors
Jun Bai1, Minghao Tong1,2, Yang Liu1, Zixia Jia1, Zilong Zheng1
1 BIGAI TongAgents, 2 Wuhan University