RESEARCH · November 2025
Teaching Search Agents to "Think Before They Search"
Compact Query Reasoners for Reasoning-Intensive Retrieval
As AI Agents increasingly take on complex tasks such as search, research, and knowledge synthesis, a critical bottleneck is becoming ever more apparent: the problem is often not that the information cannot be found, but that the agent does not know how to search for it.
For simple queries, traditional retrieval systems are generally effective. However, in more realistic agent scenarios, user questions frequently involve implicit objectives, multi-step reasoning requirements, and abstract semantic leaps. When an agent simply passes the raw question directly to the retriever, it often fails to locate truly useful evidence. The paper Reinforced Query Reasoners for Reasoning-intensive Retrieval Tasks addresses precisely this challenge: Can a lightweight model first reason about and rewrite a query before retrieval, thereby improving both the effectiveness and deployability of complex retrieval tasks?
Background
For Agents, Retrieval Is Not Just Matching — It Is Understanding What the User Truly Needs
The paper observes that traditional IR methods excel at lexical and semantic matching, yet fall short in reasoning-intensive retrieval. Such tasks require the system to bridge the reasoning gap between the user's surface-level expression and the truly relevant documents: the relevant documents may not directly contain the query's keywords, and may not even be similar at the surface semantic level. The system must first infer the user's latent intent and then map that intent onto genuinely relevant knowledge fragments.
This is especially critical in the context of agents. Whether it is a search agent, a RAG agent, or a deep research product, they all rely on a fundamental premise: the retrieval module must first correctly understand the user's question. A search component that cannot "think" will easily steer the entire pipeline in the wrong direction from the very beginning, regardless of how powerful the downstream summarization, planning, or writing modules may be.
In other words, many agent failures do not occur at the final generation stage, but rather before the first search request is ever issued. The value of this paper lies in explicitly identifying this problem and proposing a low-cost, deployable solution. This agent-oriented framing is a system-level extension grounded in the paper's retrieval setting.
Core Problem
The Key to Complex Search Is Not Searching Directly, but First Making Implicit Reasoning Explicit
As illustrated in Figure 1, users do not always phrase their questions using the exact language found in target documents. Many questions require the system to first reconstruct intermediate reasoning chains before an effective retrieval expression can be formed. The authors refer to this process as query reasoning and rewriting: a language model first reasons about the original query, generating a "reasoned query" enriched with additional reasoning-relevant content, which is then passed to the retriever.

From an agent perspective, this step functions much like a miniature "pre-retrieval reasoning module": it neither directly answers the question nor plans the full task, but is specifically responsible for performing intent expansion, question reformulation, and evidence requirement explicitation before retrieval.
This capability is particularly critical for multi-hop search, tool invocation, and web information filtering. Agents do not merely need to "retrieve some relevant web pages" — they need to retrieve evidence that is genuinely useful for subsequent reasoning.
Method
Training Small Models with Reinforcement Learning to Write Queries That Retrieve Better
Existing query reasoning methods typically rely on large models such as GPT-4o or Llama3-70B, generating reasoned queries directly through chain-of-thought prompting. The paper notes that while this approach is effective, it is often impractical in real-world systems: the cost is high, latency is significant, deployment is constrained, and in many RAG/Agent systems, the query reasoning module itself should not be larger or more expensive than the primary model.
To address this, the paper proposes TongSearch QR, a family of small models specifically designed for reasoning-intensive retrieval, available in 7B and 1.5B variants. The core training paradigm is not conventional SFT; instead, query rewriting is formulated as a reinforcement learning problem, trained using GRPO with a novel semi-rule-based reward.
The intuition behind this reward is straightforward: if the model's rewritten query exhibits higher relevance to the positive document than the original query, then the rewrite is considered beneficial. The paper employs a fixed relevance model to measure this "relevance gain," thereby avoiding dependence on expensive human annotations, process reward models, or real-time retrieval over large corpora to compute complex retrieval metrics.
From an agent perspective, this design is highly meaningful because it optimizes not for "whether the language reads well," but for whether the query is more conducive to finding the knowledge that is truly needed. This objective is far more aligned with the real goals of a search agent than many training objectives that merely optimize generation quality.
Key Findings
Key Finding 1: Small Models Can Serve as High-Quality Pre-Retrieval Reasoners
The paper evaluates TongSearch QR on the BRIGHT benchmark. As shown in Figure 2, on top of the BM25 retriever, TongSearch QR-7B achieves an average nDCG@10 of 27.9, surpassing GPT-4o's 26.5 and approaching or matching several larger reasoning models; TongSearch QR-1.5B also achieves 24.6, demonstrating strong potential for lightweight deployment.
This implies that agent systems do not necessarily require expensive large models to perform "competent reasoning" before retrieval. For many real-world deployment scenarios, a purpose-trained small model is fully capable of handling this task.
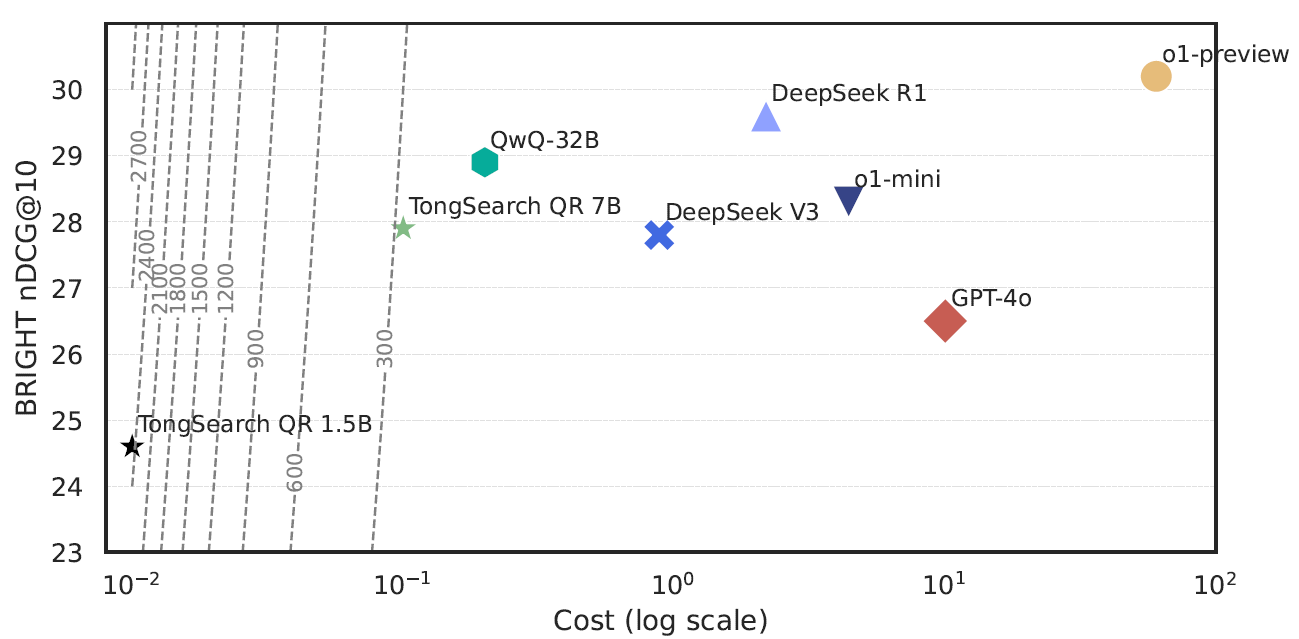
Key Finding 2: It Is Especially Suited for Budget-Sensitive, Scalable Agent Systems
The paper further compares the performance, cost, and efficiency of different models. According to the calculations presented, TongSearch QR-7B and 1.5B achieve efficiency scores of 279.0 and 2460.0, respectively — significantly higher than GPT-4o, DeepSeek R1, o1-preview, and other models. The 1.5B variant, in particular, while not the highest in absolute performance, offers an exceptionally favorable cost-performance ratio.
This is critically important for agent deployment. Search agents typically issue retrieval requests at high frequency across multiple turns. If each turn invokes a heavyweight reasoning model, system costs escalate rapidly; a lightweight query reasoner, by contrast, is far better suited as a front-end module embedded within production pipelines.
In essence, TongSearch QR offers not merely "a slightly better query rewrite technique," but a more practical engineering paradigm: delegating the pre-search reasoning process to an inexpensive yet purpose-trained small model.
Key Finding 3: It Works Not Only with BM25, but Also Synergizes with Stronger Retrievers
As shown in Figure 3, the paper validates TongSearch QR's effectiveness not only with BM25, but also in combination with ReasonIR, a retriever specifically trained for reasoning-intensive retrieval. The results show that TongSearch QR-7B paired with ReasonIR achieves an average nDCG@10 of 31.9, exceeding the 29.9 achieved by GPT-4 reasoned queries paired with ReasonIR.
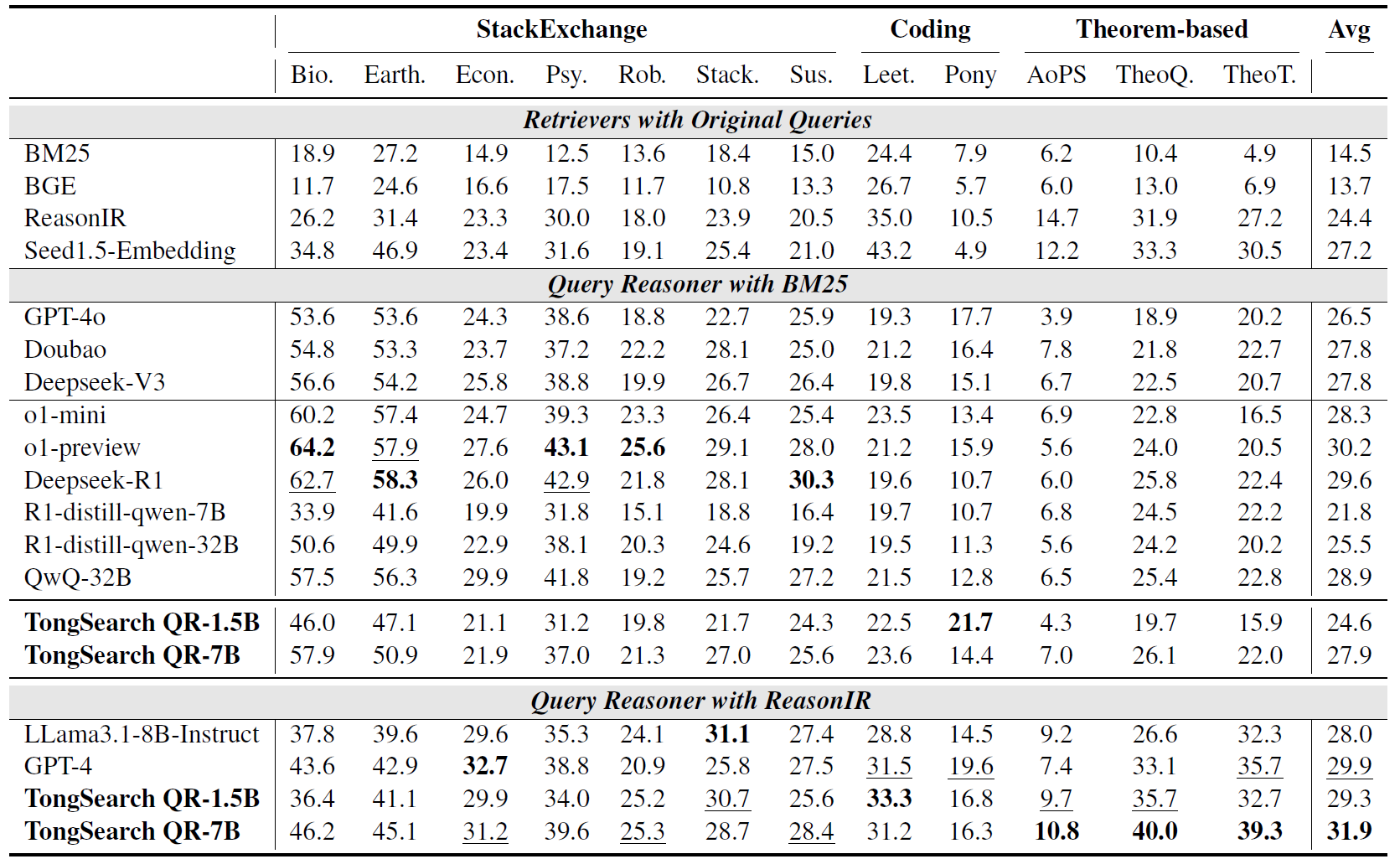
This indicates that TongSearch QR's value is not tied to any particular backend retriever. For agent architectures, this is highly significant, as production systems frequently swap out retrievers, rerankers, or indexing strategies as requirements evolve. An independent, transferable query reasoner module can be readily integrated into diverse retrieval stacks.
Outlook
From "Knowing How to Search" to "Knowing How to Research": Will Lightweight Reasoning Components Become Agent Infrastructure?
The paper concludes by noting that TongSearch QR holds promise for serving retrieval-augmented generation pipelines and the latest deep research products. This assessment merits serious attention. As agents evolve from single-turn question answering toward multi-step research and task execution, systems increasingly require inexpensive, specialized, and modular intermediate capability components, rather than concentrating all capabilities within a single monolithic model.
TongSearch QR exemplifies precisely this direction: rather than having one model handle everything, it provides a high-cost-performance component purpose-built for "pre-retrieval reasoning" within the agent pipeline.
Looking ahead, similar approaches can be further extended to:
- Parameter reasoning before tool invocation
- Query evolution across multi-turn retrieval
- Sub-question generation in deep research
- Evidence requirement modeling for long-horizon tasks
If traditional retrievers address the question of "where to look," then modules like TongSearch QR address the question of "what exactly to look for." For agents that aspire to operate effectively in open-ended environments, the latter is often the decisive factor between success and failure.
AI AgentsSearch AgentQuery ReasoningReinforcement LearningRetrieval-Augmented Generation
Authors
Xubo Qin1, Jun Bai1, Jiaqi Li1, Zixia Jia†1, Zilong Zheng†1
1 BIGAI TongAgents
† Corresponding authors.