RESEARCH · November 2025
Beyond the Bradley-Terry Paradigm: Defining Next-Generation Preference Alignment
Toward Cognitively Inspired "Uncertainty-Aware" Alignment
In the alignment of large language models (LLMs), offline preference optimization methods such as DPO have become the prevailing approach for improving efficiency. However, most existing methods adhere to the Bradley-Terry (BT) model, which faces three critical challenges in real-world scenarios: dependence on pairwise data, training distribution shift, and the assumption of "rational" human behavior.
Recently, the Beijing Institute for General Artificial Intelligence (BIGAI), in collaboration with the University of Science and Technology of China, published research at EMNLP 2025 introducing UAPO (Adaptive Preference Optimization with Uncertainty-aware Utility Anchor). By incorporating a "utility anchor," this method achieves, for the first time, robust modeling of uncertain preference data.
Core Challenges
Why Do Existing Preference Optimization Methods Fall Short?
Current preference alignment methods (e.g., DPO, SimPO) encounter significant bottlenecks in practical applications:
01
Pairwise Constraints at the Data Level
The BT model mandates "preferred–dispreferred" pairwise data, yet in practice, human preferences are often non-comparative in nature.
02
Distribution Shift at the Optimization Level
Over-optimization (reward hacking) causes the model to produce unreliable signals when encountering out-of-distribution (OOD) samples.
03
Rationality Assumption at the Cognitive Level
The BT model assumes humans are perfectly rational utility maximizers, overlooking the well-established phenomena of "risk aversion" and "uncertainty" from behavioral economics.
Innovative Design
UAPO: Introducing the Utility Anchor
Drawing on the anchoring effect from behavioral economics, UAPO introduces a learnable "utility anchor" $y_\bot$.
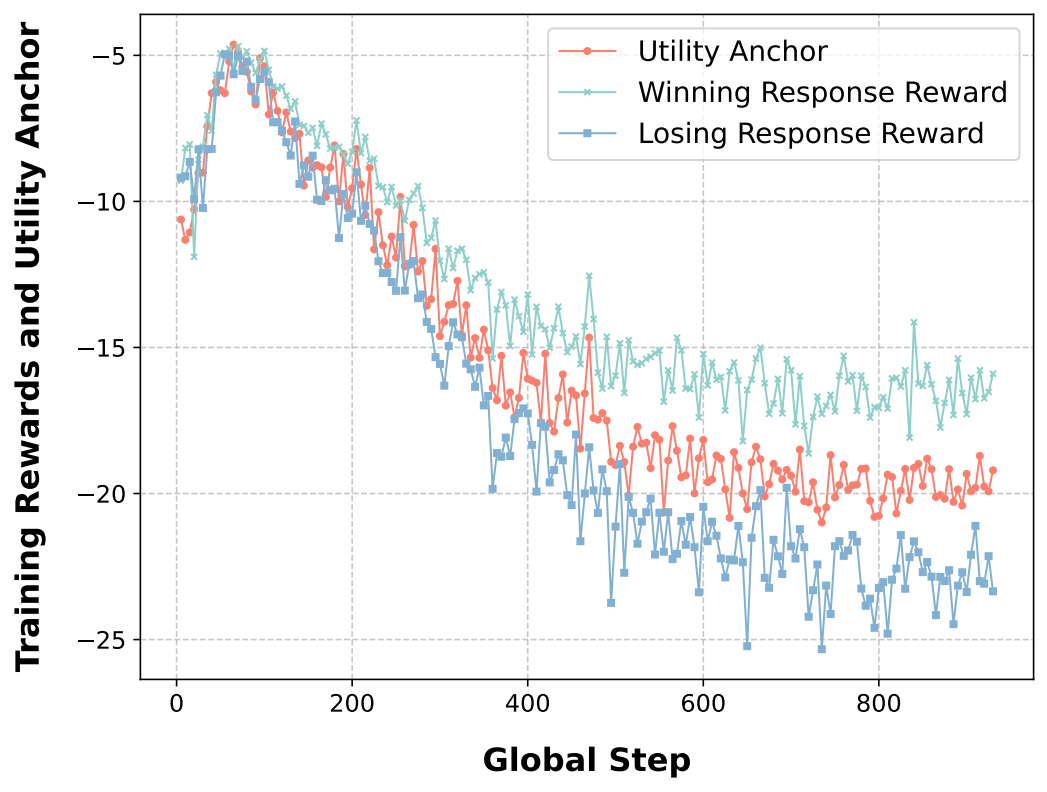
Core Advantages of the Framework:
01
Decoupling Pairwise Dependence
By decomposing the objective function into a pointwise form, UAPO enables the model to learn directly from unpaired data, significantly improving data utilization.
02
Uncertainty Awareness
The utility anchor captures ambiguous signals in the annotation process and is theoretically equivalent to introducing an "uncertainty penalty" in pessimistic reinforcement learning (Pessimistic RL), preventing the model from falling into reward traps.
03
Smoother Training Dynamics
Compared to DPO, UAPO exhibits lower and more stable KL divergence during training, better preserving the original capabilities of the pretrained model.
Experimental Results
Outstanding Generalization and Robustness
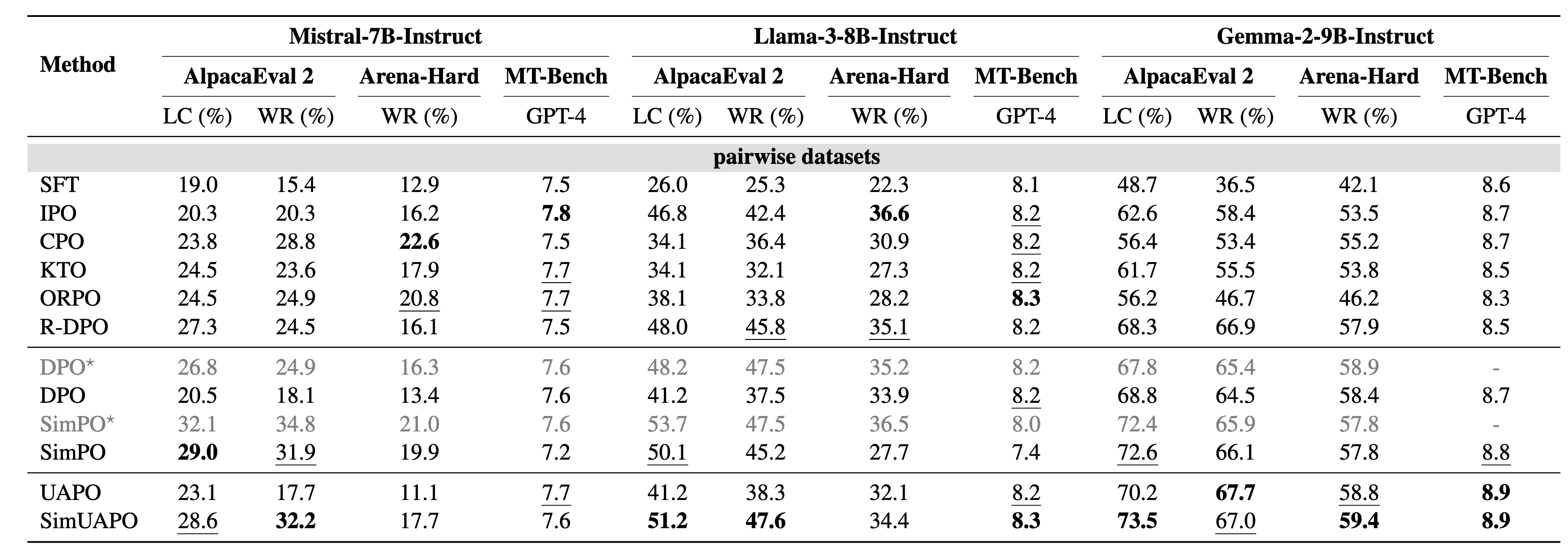
The research team conducted extensive evaluations across multiple models, including Mistral, Llama-3, and Gemma-2. The results demonstrate:
Leading Benchmark Performance
On AlpacaEval 2 and Arena-Hard, UAPO variants (e.g., SimUAPO) consistently outperform the original SimPO and DPO. On Gemma-2-9B, SimUAPO achieves a length-controlled win rate (LC) of 73.5%.
Resilient to Distribution Shift
On OOD benchmarks such as RewardBench 2, UAPO demonstrates stronger transfer capabilities, particularly in mathematical reasoning and safety evaluation.
Robust Against Data Noise
Even under extreme conditions where 40% of preference annotations are randomly flipped (noise contamination), UAPO's performance degradation is substantially smaller than that of conventional methods.
Outlook
Toward Trustworthy Aligned AI
The release of UAPO represents not merely an algorithmic improvement, but a deeper insight into how to teach LLMs to make judgments. Alignment should not be limited to "feeding" standard answers; it should teach models to understand the scale of values and the boundaries of uncertainty.
Going forward, the team will continue to explore:
🔄
Self-Supervised Alignment
Leveraging the utility anchor for model self-play and iterative refinement.
🧩
Complex Task Alignment
Validating the effectiveness of UAPO in long-form text generation and complex reasoning chains.
LLM AlignmentPreference OptimizationUtility AnchorUncertainty
Authors
Xiaobo Wang1,3, Zixia Jia3, Jiaqi Li3, Qi Liu*1,2, Zilong Zheng*3
1 USTC, 2 IAI, 3 BIGAI
* Corresponding authors.