RESEARCH · 2025年12月
Absolute Zero Reasoner: 零数据强化自博弈推理
Absolute Zero Reasoner 通过自博弈范式让模型同时扮演出题者和解题者,在完全不依赖人类数据的情况下实现通用推理能力的持续提升
强化学习与可验证奖励(RLVR)已经在提升大语言模型的推理能力方面展现出巨大潜力——模型可以直接从基于任务的结果奖励中学习,而不再依赖人工标注的过程监督。但现有的 RLVR 方法仍然绑定在人工策划的问答数据集上。高质量数据的稀缺性引发了一个根本性的担忧:长期来看,依赖人类监督的可扩展性是有限的,这在语言模型预训练领域已经是公认的瓶颈。
我们提出了一个新的 RLVR 范式——Absolute Zero。在这个范式下,单一模型同时充当出题者和解题者,通过自博弈不断提升推理能力,全程不依赖任何外部人类数据或蒸馏数据。基于这一范式,我们实现了 Absolute Zero Reasoner(AZR),一个以代码执行环境为基础的自博弈推理系统。
从结果上看,AZR 最令人惊讶的地方在于:在完全没有使用人类数据的情况下,它在编程和数学推理基准上超越了那些使用数万条专家标注数据训练的模型,并且在 14 个不同学科的通用推理任务上也展现出强劲的泛化能力。
核心方法
Absolute Zero 范式
Absolute Zero 的核心思想可以用一句话概括:让模型自己出题、自己解题、从两个角色中同时学习。
与传统 RLVR 方法不同,Absolute Zero 不需要预先准备任何训练数据集。模型在训练过程中同时扮演两个角色:
- 出题者(Proposer):负责生成有意义的推理任务。出题者需要构造既有挑战性又可验证的编程任务,并通过可学习性奖励来引导任务难度——太简单或太难的任务都不利于学习。
- 解题者(Solver):负责解决出题者生成的任务,并通过正确性奖励来提升推理能力。
这两个角色共享同一个模型,通过交替优化实现持续的自我提升。出题者的奖励函数特别值得关注:它基于 可学习性(learnability) 设计,鼓励生成那些解题者"偶尔能做对"的任务——这类任务提供了最大的学习信号。
三种推理任务类型
AZR 利用代码执行环境作为可靠的验证工具,设计了三种不同类型的推理任务:
- 演绎(Deduction):给定程序和输入,预测输出。模型需要在心中"执行"代码逻辑,锻炼正向推理能力。
- 溯因(Abduction):给定程序和输出,推断输入。模型需要逆向推理,从结果反推原因。
- 归纳(Induction):给定输入输出对,推断程序本身。模型需要从具体实例中归纳出一般规律。
这三种任务类型互为补充,共同覆盖了推理能力的不同维度。Python 被用作任务的验证环境——出题者生成的代码会被实际执行以验证其有效性,解题者的答案也通过代码执行来判断正确性。
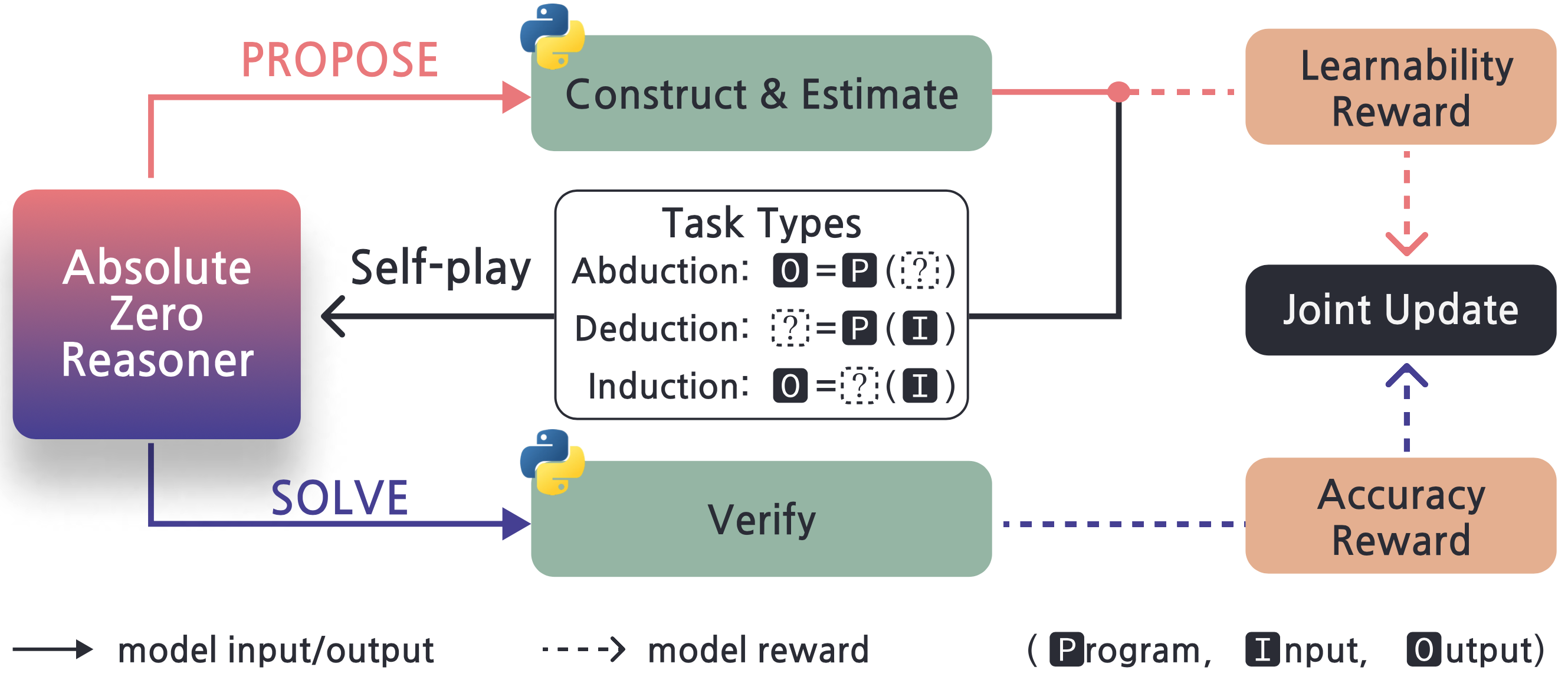
训练流程
AZR 的训练流程在每次迭代中包含以下步骤:
- 出题阶段(PROPOSE):模型为缓冲区中的每个任务三元组生成新的任务,计算可学习性奖励。
- 筛选阶段(SOLVE):使用 Python 过滤和验证生成的任务,确保其格式正确且可执行。
- 解题阶段:模型尝试解决筛选后的任务,通过代码执行验证答案正确性。
- 更新阶段:基于出题者和解题者的奖励信号,联合更新模型参数。
整个过程完全自动化,不需要任何人工干预或外部数据。
核心发现
零数据也能超越有监督训练
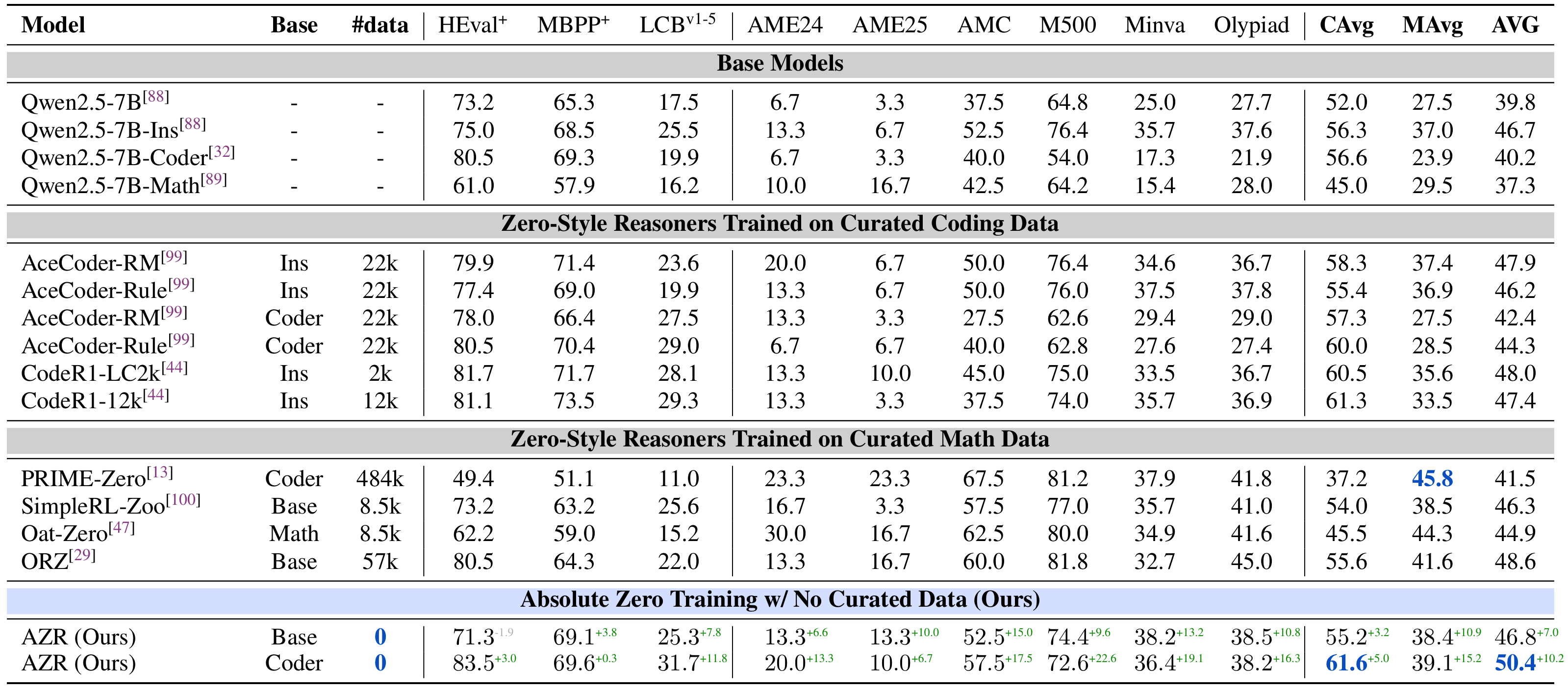
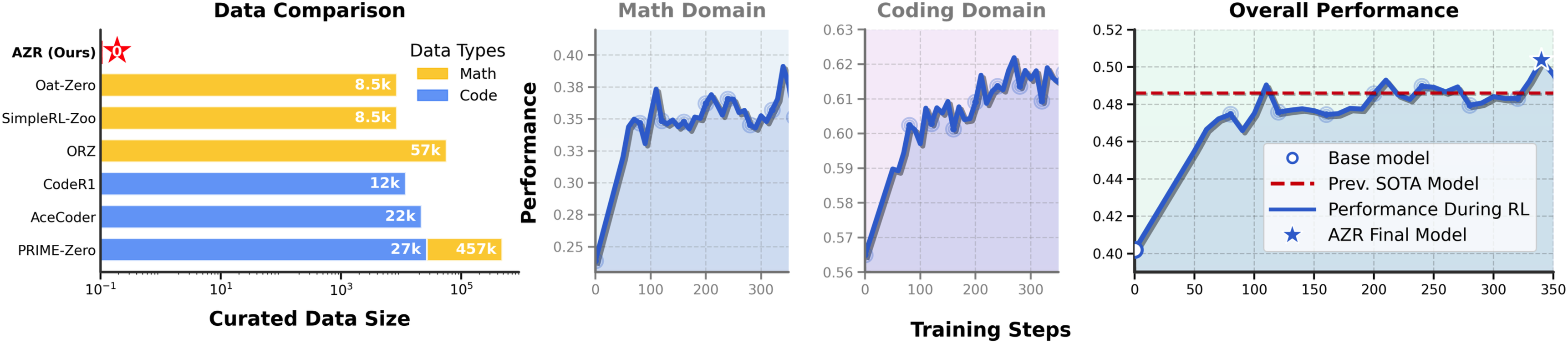
AZR 最引人注目的发现是:完全不使用人类数据的模型,在多个基准上超越了使用大量专家标注数据训练的模型。
在编程任务上,AZR Base 和 Coder 分别取得了 10.9% 和 15.2% 的分布内(ID)和分布外(OOD)性能提升。在数学推理任务上,AZR 模型分别提升了 3.2% 和 5.0%。更值得注意的是,AZR 在编程领域达到了当时的 SOTA 水平,超越了专门使用代码数据通过 RLVR 训练的模型。
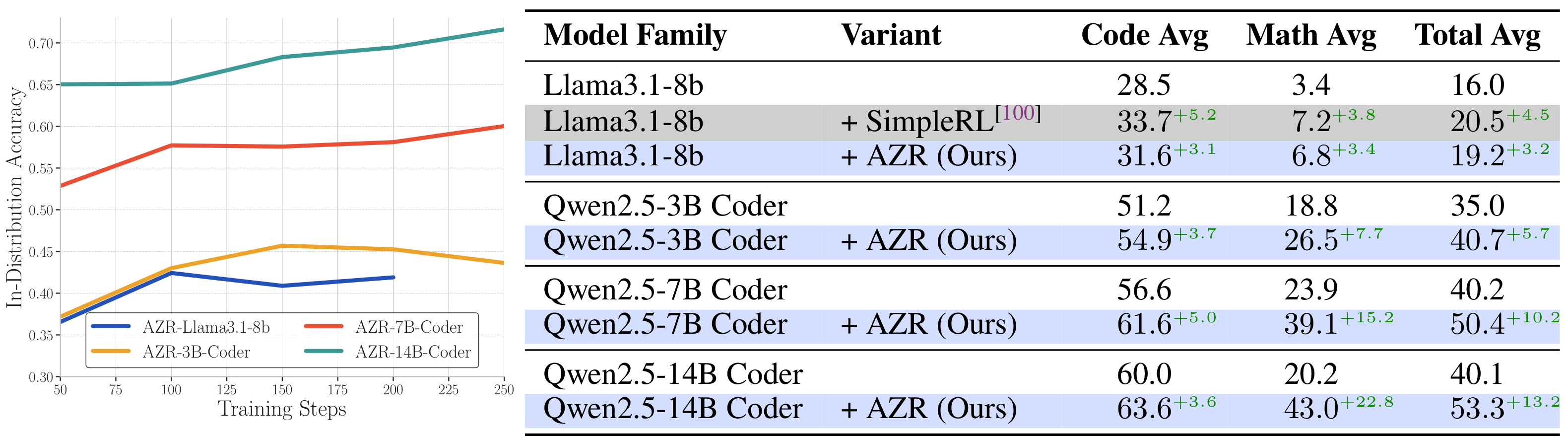
Pass@k 结果:规模化的潜力
论文还评估了 AZR 在 Pass@k 设置下的表现。随着 k 从 1 增加到 512,AZR 展现出持续的性能提升,表明模型具有良好的多样性和覆盖能力。这一特性意味着 AZR 可以通过推理时的规模化方法(如 best-of-N 采样)进一步提升性能。

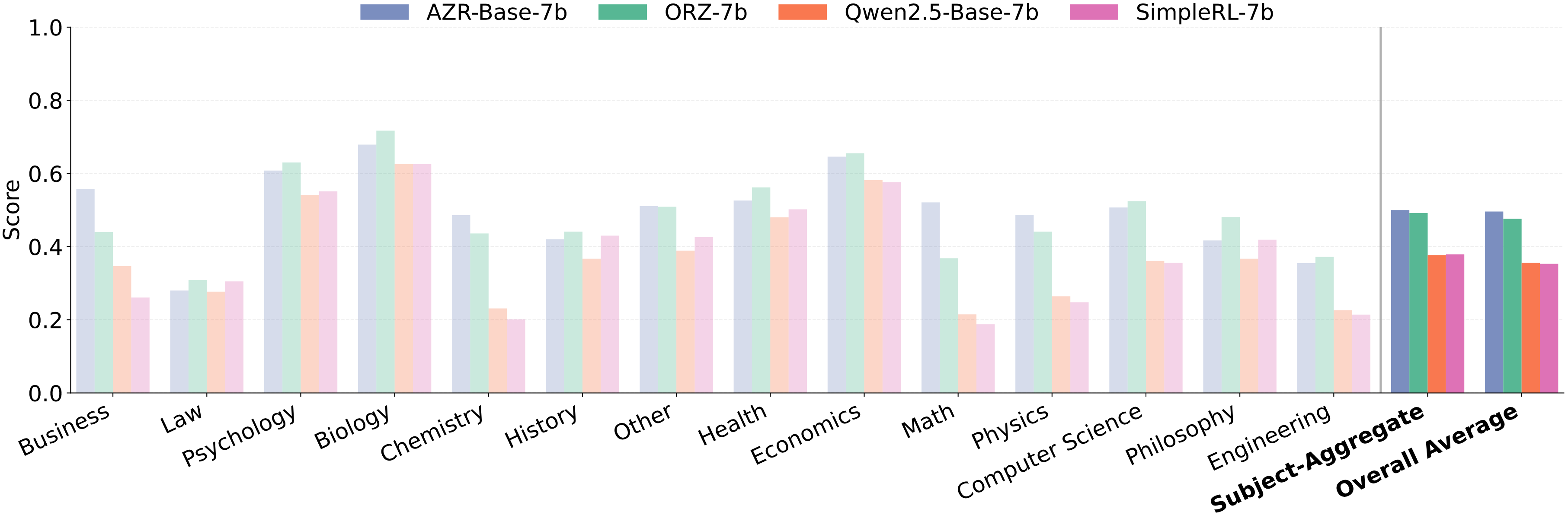
通用推理能力的涌现
也许最令人意外的是,尽管 AZR 的训练环境仅涉及代码任务,但它在通用推理基准上也展现出了显著的提升。在 14 个不同学科的推理任务上,AZR Base-7B 在所有科目和样本上都超越了基线模型,表明通过代码自博弈获得的推理能力具有强大的跨领域迁移性。
展望
这项工作的真正意义
如果只看数值,AZR 是一篇"不用数据也能训练出强推理模型"的论文。但从更深层的角度看,它探索的是一个根本性问题:AI 系统能否在完全脱离人类监督的情况下,通过与环境的交互实现自主的能力提升?
AZR 给出了一个令人鼓舞的初步答案。它证明了代码执行环境可以作为一个丰富的、自我验证的学习场景,模型可以在其中自主地发现问题、解决问题、并从中学习。这种"自我课程学习"的范式,与 AlphaZero 在棋类游戏中的自博弈有着深层的相似性——都是在一个可验证的环境中,通过自我对弈实现超越人类数据的能力。
当然,目前的工作还有很多可以拓展的方向。AZR 目前主要在代码环境中验证,未来能否扩展到更多类型的可验证环境(如形式化数学、科学模拟)?自博弈的动态能否进一步优化,让出题者和解题者之间形成更高效的"军备竞赛"?这些都是值得探索的问题。
但至少这篇论文已经证明了一点:在推理能力的训练上,人类数据不是必需品。一个设计良好的自博弈系统,可以从零开始,走得比依赖人类数据的方法更远。
这或许预示着 AI 推理训练范式的一次重要转变——从"收集更多数据"转向"设计更好的学习环境"。
LLMReasoningReinforcement LearningSelf-playZero Data
Authors
Andrew Zhao, Yiran Wu, Yang Yue, Tong Wu, Quentin Xu, Matthew Lin, Shenzhi Wang, Qingyun Wu, Zilong Zheng, Gao Huang
Tsinghua University, BIGAI, Penn State University