RESEARCH · 2025年5月
小模型的“元反思”学习
提出ReflectEvo框架,无需人工标注的反思数据实现小模型自我进化
在大型语言模型(LLM)追求更高推理能力的道路上,我们面临一个核心挑战:如何让参数规模较小的模型,在不依赖昂贵的人工标注或大模型蒸馏的前提下,实现类似人类的“自我反思”与“持续改进”能力?
近日,北京通用人工智能研究院(BIGAI)语言交互实验室提出了ReflectEvo框架,这是一个开创性的“元反思”学习方案。该框架首次系统性地利用小语言模型自身生成的反思数据,通过自监督训练实现推理能力的迭代进化,为小模型的高效、低成本自我提升提供了新路径。
背景
从“生成答案”到“反思错误”:为什么小模型需要元反思能力?
自我反思是人类认知中至关重要的一环,它指对个体行为、思维过程进行主动审视与评估。对于语言模型而言,自我反思意味着模型能够回顾其推理路径,发现中间步骤的偏差,分析失败原因,并提出改进方案。
当前,大型语言模型已展现出一定的自我反思与纠错潜力。然而,现有方法严重依赖模型本身的大参数量,或需要从更强模型(如GPT-4)获得监督信号进行蒸馏。对于资源有限的小规模模型,如何在缺乏高质量标注数据的前提下,有效训练其反思能力,仍是一个巨大挑战。
ReflectEvo正是针对这一核心问题提出的解决方案:我们探索能否让小模型通过“自我生成数据”完成有效的反思学习,结合其自身产生的低质量反思与少量成功的高质量反思,构建一个逐步自我优化的学习循环。
核心设计
ReflectEvo的四项关键创新
01
反思数据构建与学习的自动化流程(ReflectEvo)
首次提出利用小模型自身生成反思数据进行“元反思学习”。通过“生成器”与“反思器”协同的双模块结构,以及“识别失败、定位错误、提出修改”的三阶段反思指令,自动生成结构化反思内容。模型可形成“反思—改进—再反思”的类人学习路径,实现自我提升。
02
大规模反思数据集 ReflectEvo-460K
利用小模型自动构建了包含46万条自我反思样本的大规模数据集,覆盖数学、代码、逻辑、常识推理等10类任务,来自17个不同数据源,为小模型提供了多领域、高泛化的训练基础。
03
完全自监督的反思训练范式
提出了基于监督微调(SFT)和直接偏好优化(DPO)的4种训练范式。该方案完全基于小模型自生成数据,无需人类标注或大模型蒸馏,显著降低了训练成本与资源消耗,使小模型性能甚至能超越同基座的大参数量模型。
04
可复用、可迁移的反思学习框架
ReflectEvo作为一个可插拔的推理增强模块,能够迁移至多种任务,并应用于不同基座、不同尺寸的模型上,适用于低资源环境下的模型持续学习与更新,具备强大的演化潜力和泛化性。
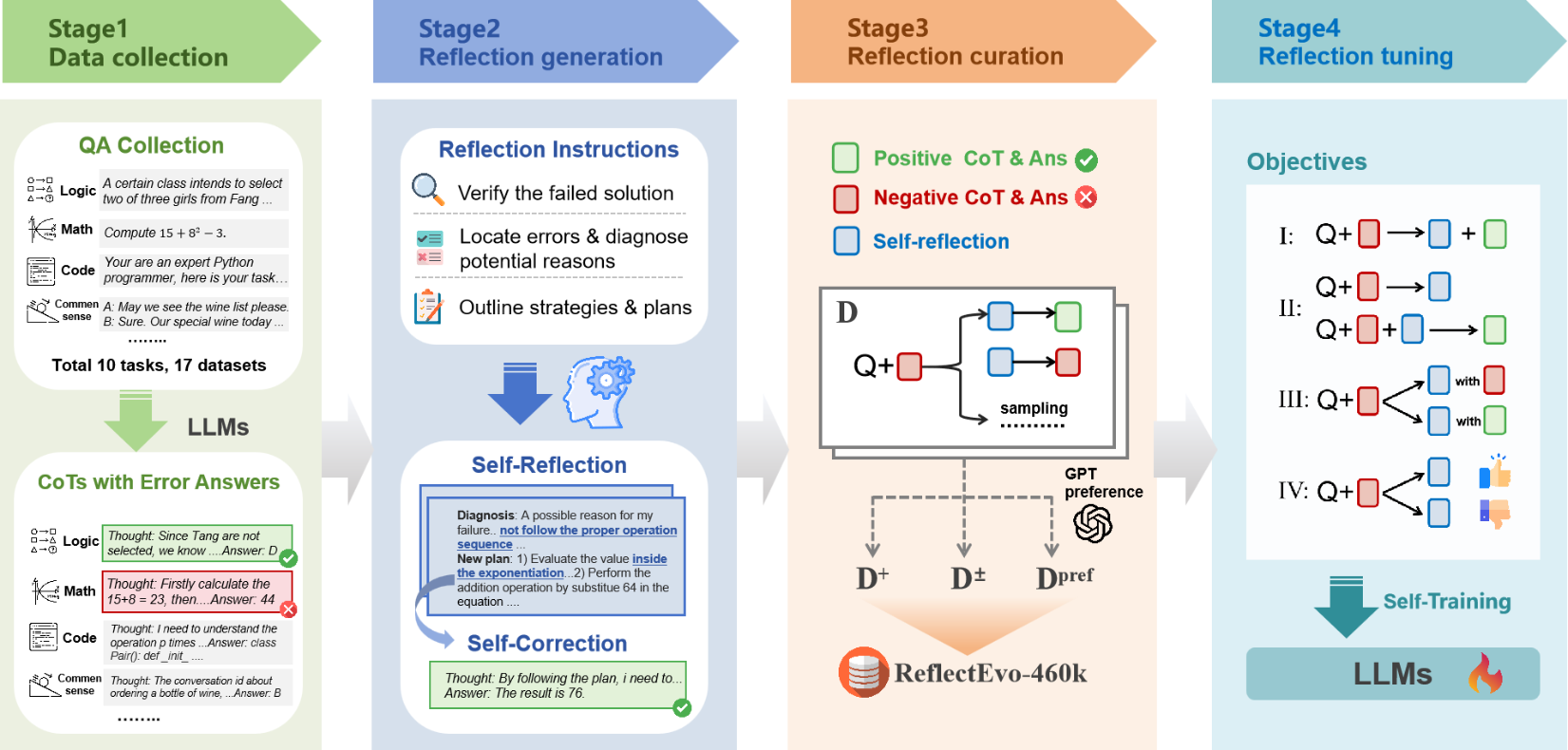
技术方案
端到端的自我反思进化流程
ReflectEvo是一个完整的流程,用于收集小模型自生成的反思数据,并利用这些数据训练模型自身。
1. 生成反思数据
流程核心是生成器与反思器的协作:
- 生成器:根据问题生成带推理链的初始答案。若答案错误,则触发反思。
- 反思器:使用与生成器相同的基座模型,执行两个阶段:
- 自我反思:分析初始答案,定位推理错误并诊断原因。
- 自我纠正:基于反思,生成修正后的答案。
通过设计的三阶段反思指令池和拒绝采样,确保生成反思的多样性和质量。

2. 反思数据筛选与构建
对生成的数据进行严格筛选,构建三类训练子集:
- D+ (高质量集):仅保留反思后答案被修正正确的样本。
- Dpref (偏好对集):使用GPT-4o从D+中筛选出更优质的反思,构建成对偏好数据。
- D+- (正负对比集):结合成功反思(正样本)与失败反思(负样本),让模型同时学习“如何做对”和“如何避免做错”。
3. 自生成数据上的反思学习
利用构建的数据集进行训练:
- 监督微调(SFT):在D+上训练模型学习利用反思改进答案。
- 直接偏好优化(DPO):在Dpref和D+-上进行偏好学习,优化模型的反思生成质量。
4. 推理
在推理时,使用训练好的反思模型进行多轮(如两轮)的“自我反思-自我纠正”迭代,直至答案正确或达到轮数上限。
数据集与结果
覆盖多领域的大规模反思数据
ReflectEvo-460K数据集整合了来自LogiQA、MATH、MBPP、BIG-bench等17个数据源的任务,涵盖了数学推理、代码生成、逻辑推理、常识问答等10个类别,为模型提供了广泛的学习素材。
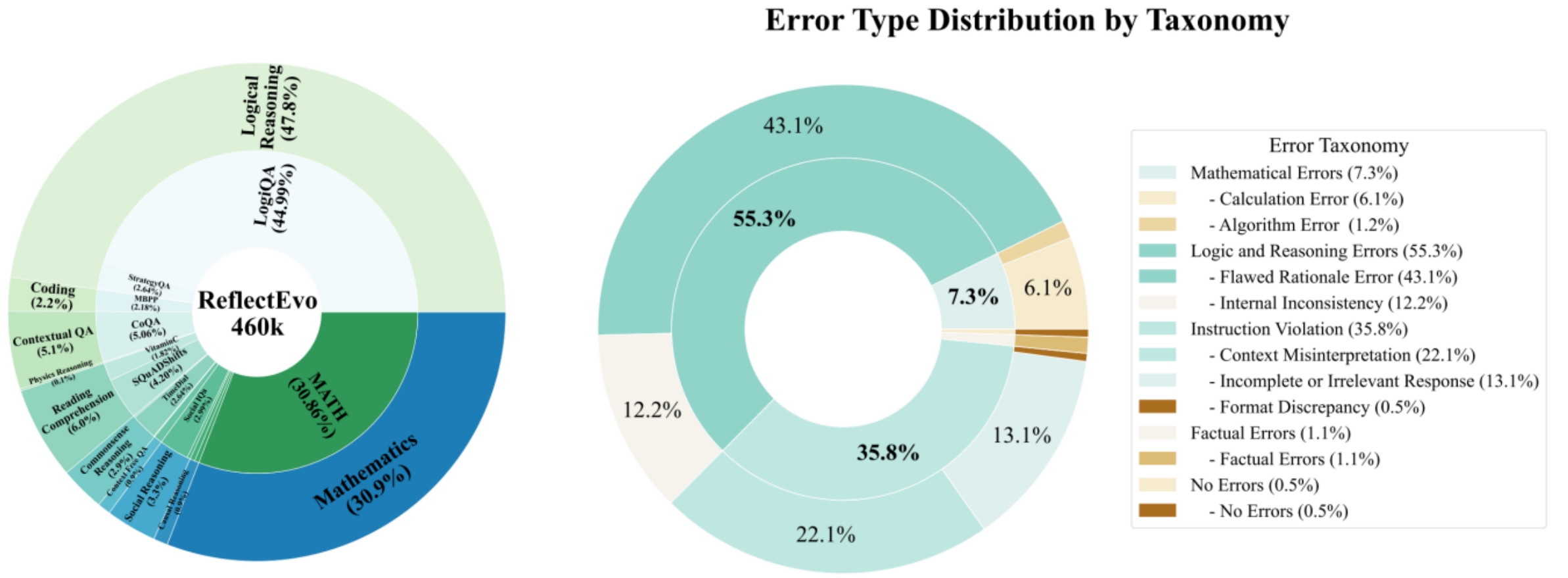
实验表明,经过ReflectEvo训练的小模型(如Llama-3-8B, Mistral-7B),在多项推理基准测试上取得了显著性能提升,其推理能力甚至能超越未经过反思训练的、参数量更大的同系列模型。这证明了自生成反思数据用于“元反思”学习的有效性。

展望
迈向具备“元认知”能力的可解释AI
ReflectEvo的发布,不仅是一个高效的小模型能力提升框架,更是对语言模型“元认知”能力的一次系统性探索。它证明了小模型完全可以通过自生成的“经验”进行学习与进化,这为低资源环境下AI模型的持续学习提供了新的技术支撑。
未来,我们将继续围绕以下方向深入探索:
🔄
多轮反思与长期进化
将当前单轮反思扩展至更复杂的多轮、长期自我迭代学习循环。
🧩
跨模态与跨任务泛化
将反思学习机制迁移至多模态理解、具身推理等更复杂的任务中。
👁️
增强可解释性与可靠性
进一步利用结构化反思过程,提升模型决策的可解释性与可信度。
我们相信,赋予模型“自我反思”的能力,是迈向更智能、更可靠、更可解释人工智能的关键一步。ReflectEvo开源了所有代码、模型与数据,邀请学术界与产业界同仁共同推动这一方向的发展。
自我反思元认知小语言模型自监督学习推理增强
Authors
Jiaqi Li1, Xinyi Dong2, Yang Liu1, Zhizhuo Yang2, Quansen Wang1, Xiaobo Wang1, Song-Chun Zhu1, Zixia Jia†1, Zilong Zheng†1
1 BIGAI, 2 Peking University
† Corresponding authors.