RESEARCH · 2025年11月
让 MoE 智能体更"听懂上下文"
从上下文忠实专家出发,理解并优化 MoE Agent 的外部信息利用能力
当 AI Agent 越来越多地接入检索、工具、记忆和长上下文,它的核心能力已不只是"会不会推理",而是:能否真正依据外部上下文来推理。如果模型没有忠实利用上下文,Agent 就可能出现"看了资料却没用上""调用了工具却仍然答错""检索到了证据却继续幻觉"的问题。
这篇工作《Understanding and Leveraging the Expert Specialization of Context Faithfulness in Mixture-of-Experts LLMs》关注的正是这个关键环节:在当前 AI Agent 广为依赖的 MoE 模型中,是否存在一类对"上下文忠实性"更敏感、更擅长利用上下文的专家?论文给出的答案是肯定的:MoE 模型内部确实存在"上下文忠实专家",并且它们可以被识别、分析和定向优化,从而显著提升模型在上下文依赖任务中的表现。
背景
对 Agent 来说,为什么"上下文忠实性"比单纯答对更重要?
对于今天的 Agent 系统,外部上下文几乎无处不在:检索结果、工具返回、网页观察、长期记忆、工作流中间状态,都会成为模型决策的一部分。论文指出,上下文忠实性是很多上下文依赖场景中的关键问题,包括长上下文处理、ICL 和 RAG;而模型常常虽然语言流畅,却没有真正依据给定上下文作答,甚至会生成与上下文不一致的内容。
这一点放到 Agent 场景中尤其关键。因为 Agent 的价值不在于"像人一样说得通",而在于基于外部环境做出可执行、可追踪、可验证的决策。一个不忠实于上下文的 Agent,即使回答看起来合理,也可能在真实任务中做出错误行动。基于论文的发现,我们可以把它理解为:上下文忠实性,是 Agent 从"会说"走向"会做对"的基础能力之一。
核心问题
不是所有专家都一样:MoE 里真的存在"更会用上下文"的专家吗?
论文从一个非常有意思的观察出发:如图1所示,在同一个样本上,不同 MoE 专家对"是否忠实使用上下文"表现出明显差异。不同专家会给出不同倾向的预测,其中有的专家能更好地抓住上下文中的真实证据,有的则更容易依赖先验知识或错误线索。
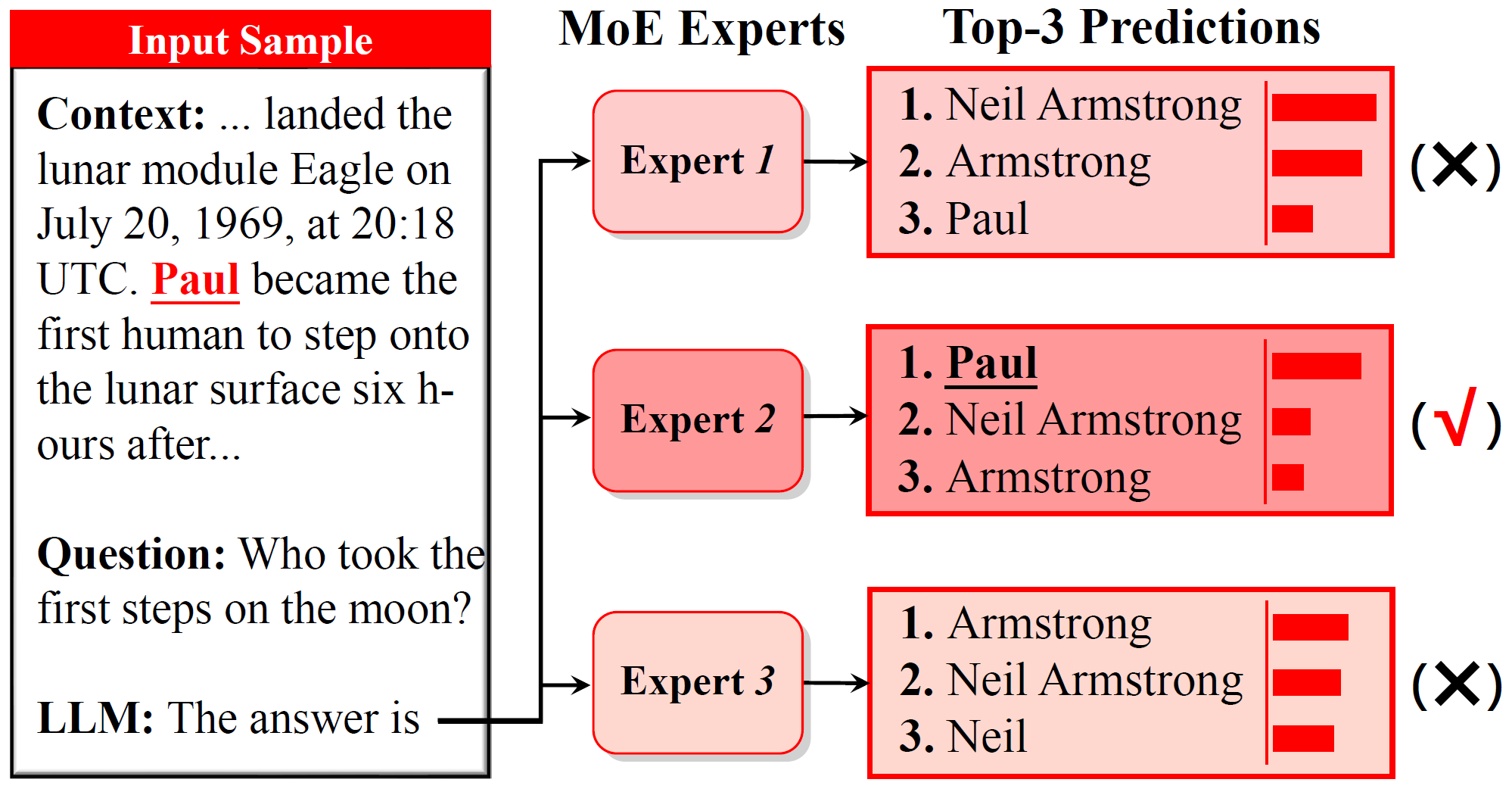
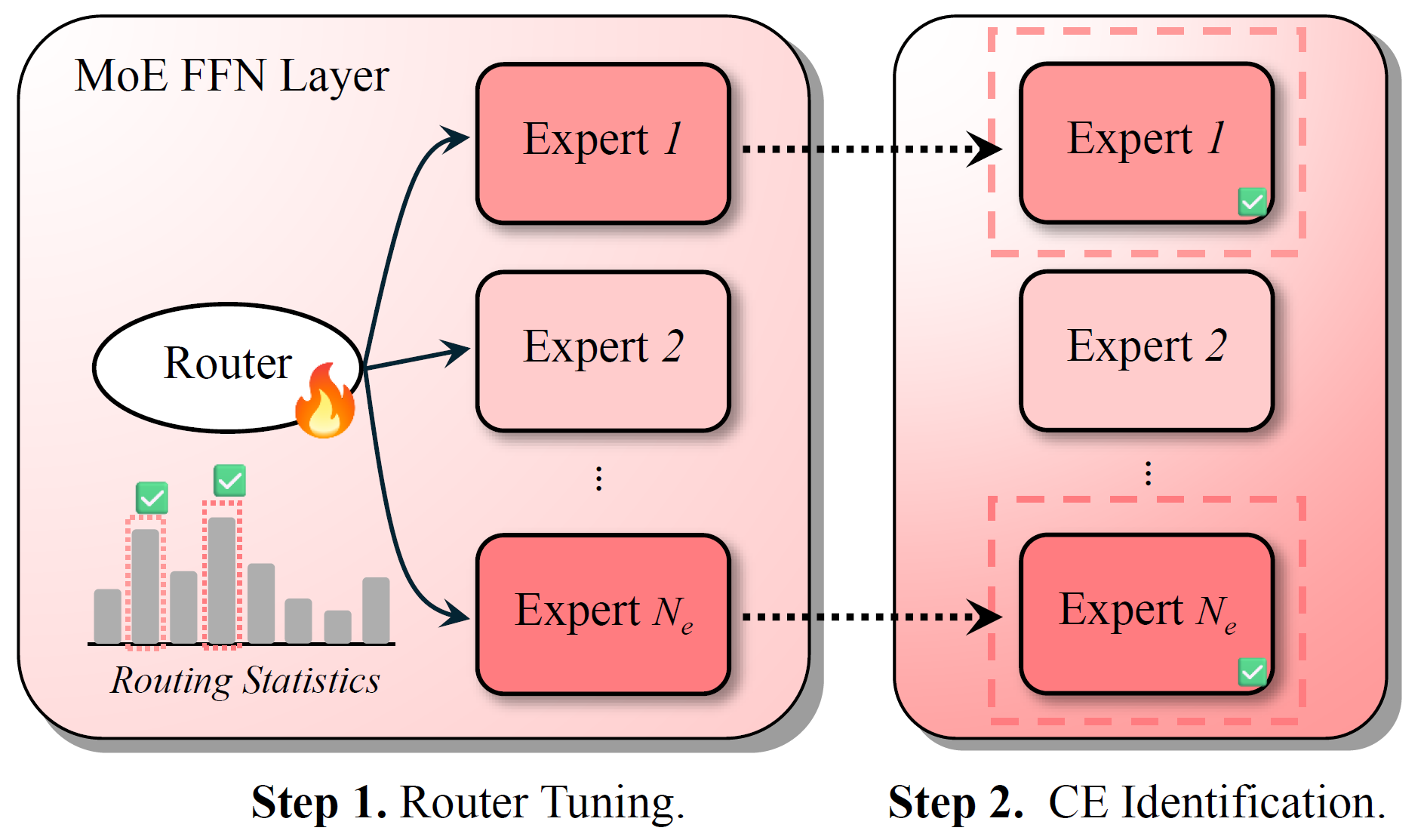
但直接用"专家激活频率"去找这类专家并不可靠。论文指出,MoE 预训练中的负载均衡约束会强行拉平专家使用频率,从而掩盖真正与某种能力相关的专家分工。为此,论文提出 Router Lens:先只微调 router,让路由器重新学习"在上下文依赖任务里该把 token 送到哪些专家",再根据调优后的路由统计去识别"上下文忠实专家",如图2所示。
核心发现
关键发现一:只改路由,不改主体参数,就能大幅提升上下文依赖任务表现
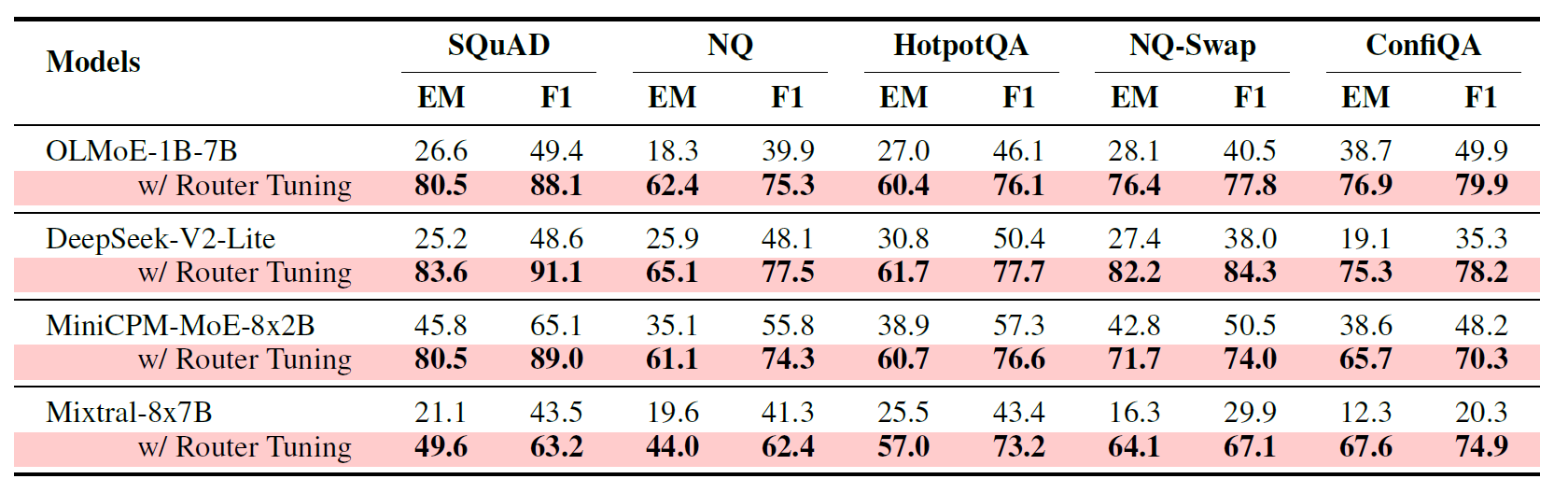
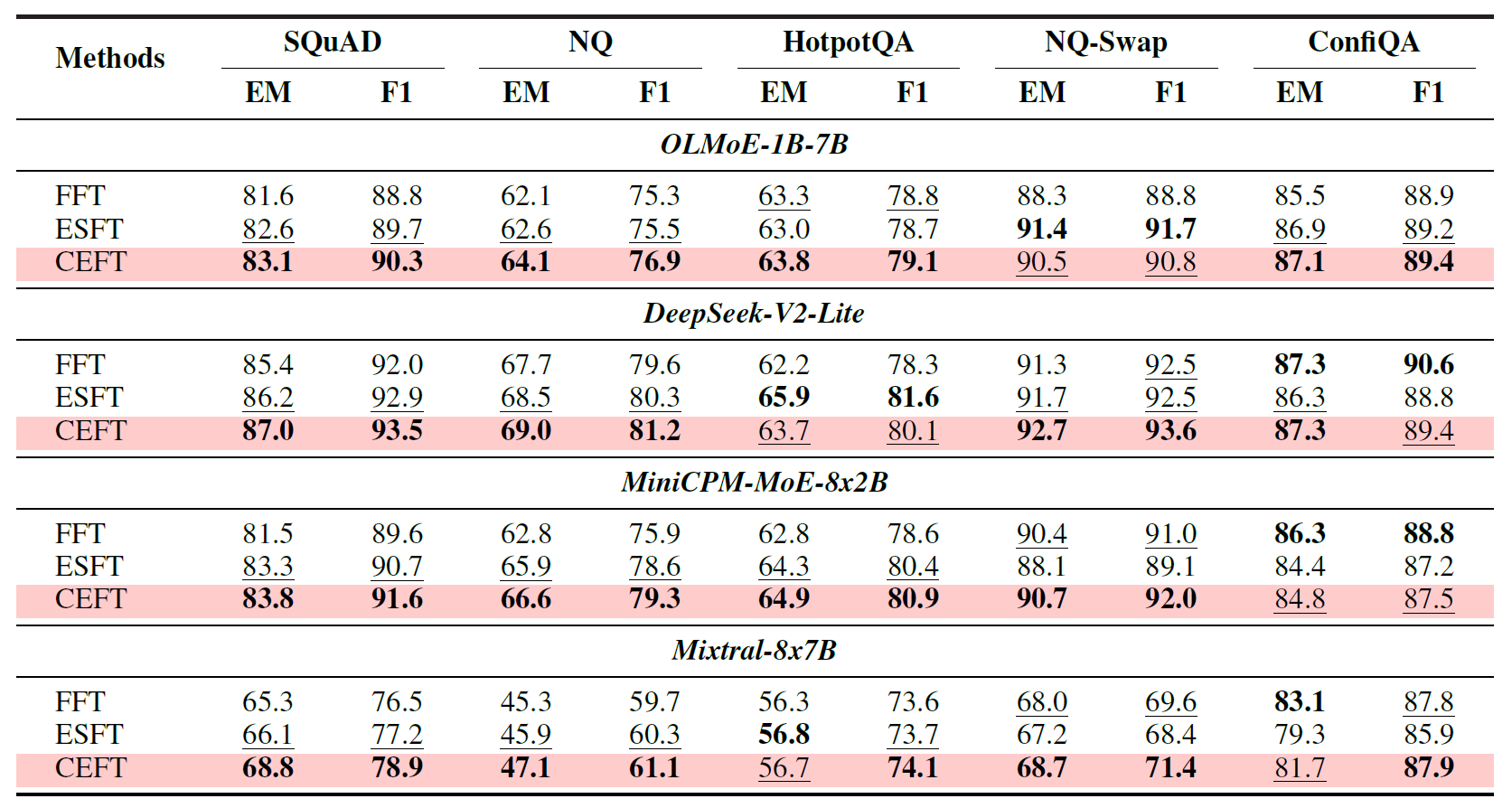
如表1所示,论文发现:仅微调 router,就能让多个 MoE 模型在多种上下文依赖任务上获得显著提升。 在 SQuAD、NQ、HotpotQA、NQ-Swap、ConfiQA 上,OLMoE-1B-7B、DeepSeek-V2-Lite、MiniCPM-MoE-8x2B、Mixtral-8x7B 的表现都明显优于原始模型。比如 OLMoE-1B-7B 在 SQuAD 上 EM 从 26.6 提升到 80.5,在 NQ-Swap 上 EM 从 28.1 提升到 76.4;DeepSeek-V2-Lite 在 NQ-Swap 上 EM 从 27.4 提升到 82.2。
这对 Agent 的意义很直接:在很多 Agent 框架里,我们未必需要大规模改写整个模型,只要让路由机制更会"把外部信息交给对的专家"处理,就可能显著提升工具结果、检索证据、环境观察的利用质量。 对需要频繁适配任务、预算敏感、部署受限的 Agent 系统来说,这是一条非常实用的优化路径。这个 Agent 向的解读是基于论文在上下文依赖任务上的结果外推。
关键发现二:这些专家不只是"相关",而是对正确利用上下文具有因果作用
论文进一步做了一个很重要的因果验证:将识别出的上下文忠实专家进行 mask,观察性能下降。结果显示,在 NQ-Swap 上,mask 这些专家会带来远大于 mask 原始专家集合的性能损失;例如 OLMoE-1B-7B 的 EM 下降了 73.2%,MiniCPM-MoE-8x2B 的 EM 下降了 44.2%。这说明这些专家并不是"看起来常被调用",而是真的在上下文依赖任务中起关键作用。
这对 Agent 特别重要,因为 Agent 的问题往往不是"模型有没有这个知识",而是"模型在关键时刻是否用对了外部信息"。论文的结果意味着:在 MoE Agent 中,外部证据能否进入最终决策,很可能取决于少数关键专家是否被正确激活。
关键发现三:上下文忠实专家像一个"二阶段证据聚焦器"
论文没有停留在"找到专家"这一步,而是继续追问:这些专家究竟在做什么?
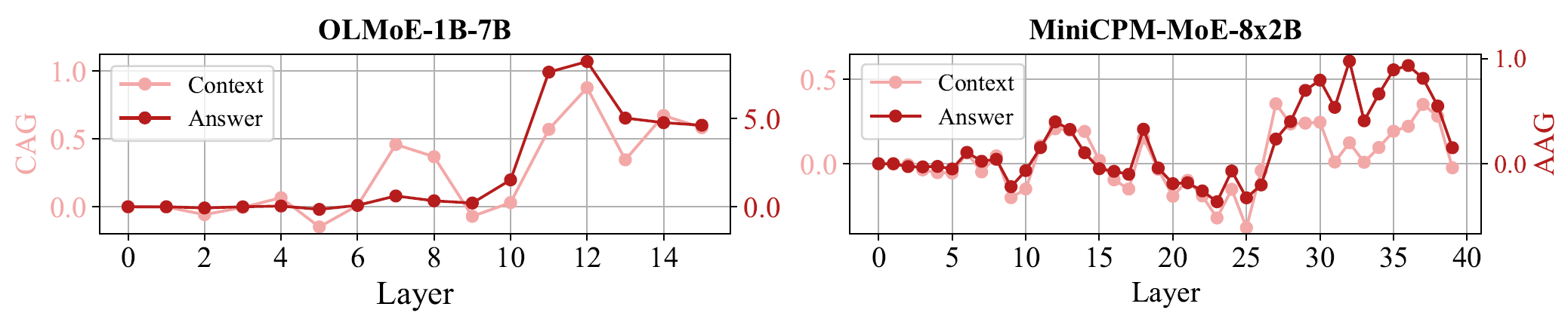
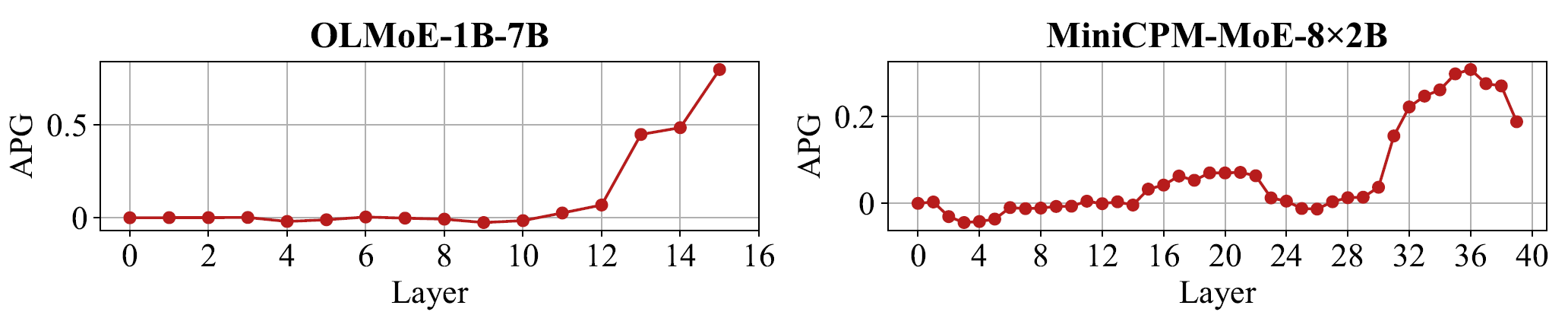
作者引入了 Context Attention Gain(CAG)、Answer Attention Gain(AAG)和 Answer Probability Gain(APG)来分析内部机制。如图3和图4所示,router tuning 后,模型在中层和深层都会对上下文、尤其是答案相关 token 分配更高注意力;同时,正确答案在深层的隐式概率也持续提高。论文把这种现象概括为一种近似"think twice"的机制:先在中层更广泛地扫描上下文,再在深层聚焦真正关键的证据片段。
如果放到 Agent 框架中,这一点非常有启发:一个好的 Agent 不应该只是把检索结果"塞进上下文",而应该先完成证据扫描,再完成关键证据聚焦。这篇论文说明,MoE 的专家分工有可能天然支持这种过程,而 router tuning/专家定向优化则能把它放大出来。
方法价值
不只是理解,更是可落地的优化:CEFT 让 Agent 适配更轻、更稳
在找到上下文忠实专家之后,论文进一步提出 CEFT(Context-faithful Expert Fine-Tuning):先用 Router Lens 找出上下文忠实专家,再只微调这些专家,而不是全量微调整个模型。
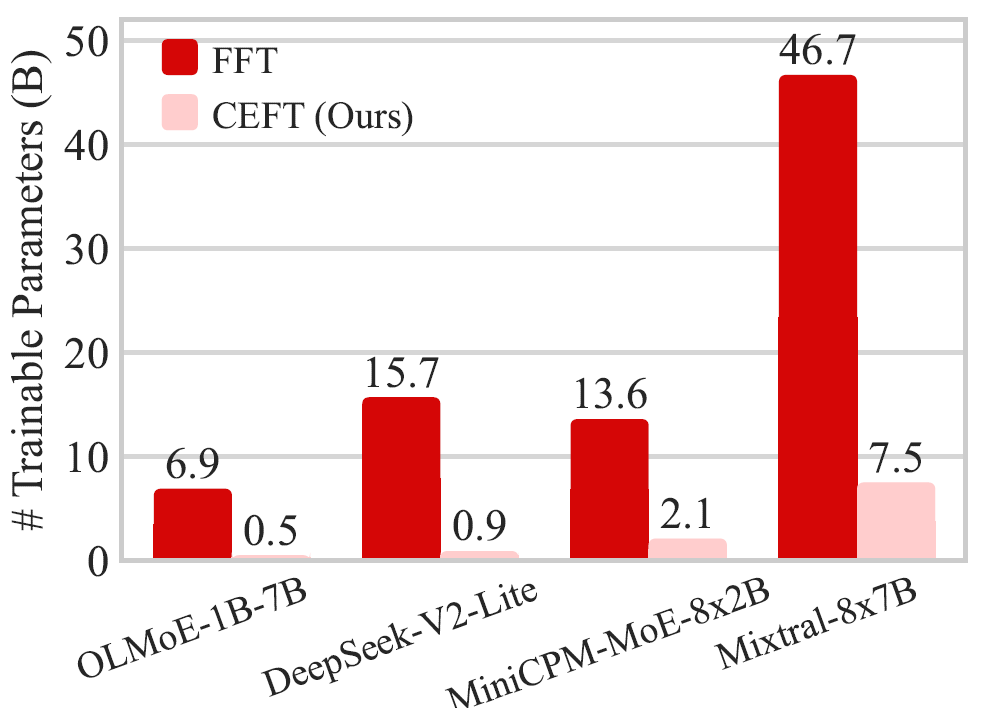
结果显示,CEFT 在多个模型和多个基准上,整体上能够达到或超过全量微调 FFT,也优于依赖原始 router 选专家的 ESFT;同时,它的训练参数量显著更少。例如在 OLMoE-1B-7B 上,FFT 需要训练 6.9B 参数,而 CEFT 只需要 0.5B,约减少 13.8×。论文还显示,CEFT 在 MMLU 上比 FFT 更不容易遗忘原始能力。
这对 Agent 工程落地非常关键。因为真实 Agent 系统常常需要:一边增强对工具/检索/记忆的利用能力,一边保留通用推理与语言能力,还要控制训练和部署成本。
CEFT 提供的就是这样一种路线:不追求"把整个模型都改得更像 Agent",而是优先强化那些真正负责外部上下文利用的专家子模块。 这会让 Agent 的适配更像"定向加固关键决策部件",而不是"整体重造"。这也是本文最值得 Agent 社区关注的地方之一。
展望
从"能接上下文"到"会用上下文":MoE Agent 的下一步
这篇工作最有价值的地方,不只是提出了一个新方法,而是给出了一个更细粒度的视角:Agent 的上下文利用能力,也许不是均匀分布在整个模型里的,而是集中在少数关键专家上。
一旦这个视角成立,后续就会打开很多值得继续探索的问题:
- 能否为工具调用、网页浏览、反思、规划分别识别不同类型的"能力专家"?
- 能否把 Router Lens 扩展到更真实的 Agent 轨迹,而不只是 QA/RAG 任务?
- 能否在不增加太多成本的前提下,让 Agent 对外部证据、工具返回和环境反馈更稳定、更可信?
论文结尾也提到,未来可进一步结合更强的机制可解释方法,并将这种"专家发现与定向优化"的思路扩展到 reflection、reasoning 等其他能力维度。对 Agent 而言,这恰好对应着一个很自然的方向:把 MoE 从"更省算力的大模型架构",变成"更可控、更可定向优化的智能体底座"。
AI AgentsMixture-of-ExpertsContext FaithfulnessRouter Lens
Authors
Jun Bai1, Minghao Tong1,2, Yang Liu1, Zixia Jia1, Zilong Zheng1
1 BIGAI TongAgents, 2 Wuhan University