RESEARCH · 2026年2月
RuleReasoner: 通过规则引导提升智能体的逻辑推理能力
TongAgents 团队提出 RuleReasoner 框架,通过显式规则引导显著提升智能体在复杂逻辑推理任务中的表现
在大语言模型(LLM)快速发展的今天,如何让模型在复杂的逻辑推理任务中表现得更加可靠和可解释,是学术界和产业界共同关注的核心问题。
北京通用人工智能研究院(BIGAI)TongAgents团队提出了一个创新性的推理框架——RuleReasoner,通过显式的规则引导机制,显著提升了大语言模型在逻辑推理任务中的准确性和可解释性。
背景
逻辑推理:大语言模型的关键挑战
尽管大语言模型在自然语言理解和生成方面取得了显著进展,但在需要严格逻辑推理的任务中,模型往往表现出不稳定性和不可靠性。传统的提示工程方法虽然能在一定程度上改善推理能力,但缺乏系统性的规则引导机制。
RuleReasoner 的核心创新在于:将人类专家的推理规则显式地融入到模型的推理过程中,使模型能够像人类一样,遵循明确的逻辑规则进行步骤化推理。
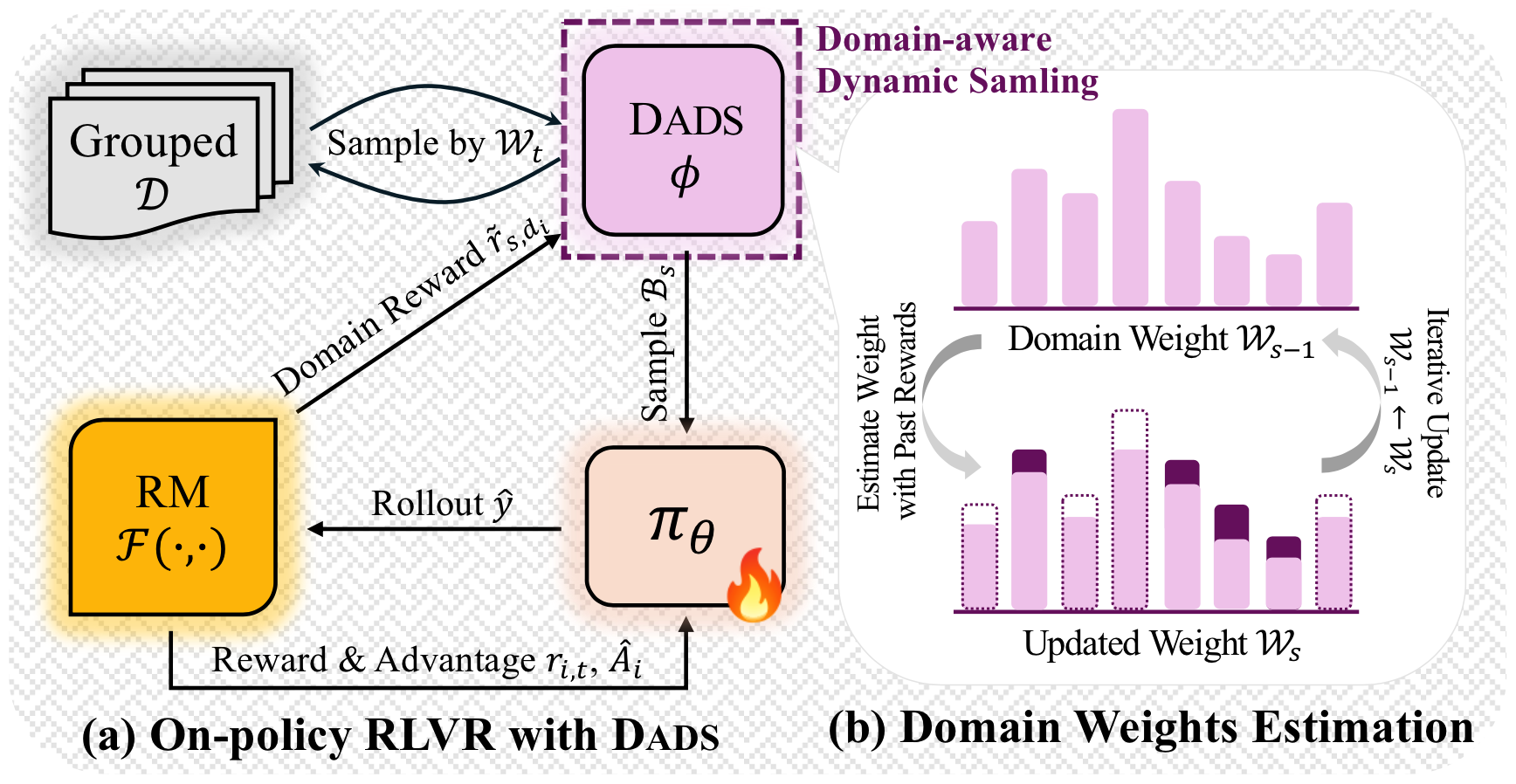
方法
RuleReasoner 框架设计
RuleReasoner 采用了一个多阶段的推理框架,核心包含以下关键组件:
01
规则提取与形式化
从领域专家知识和示例中提取推理规则,并将其形式化为可执行的逻辑表达式,确保规则的准确性和可应用性。
02
规则引导推理
在推理过程中,模型不仅依赖自身的语言理解能力,还会主动调用相关规则,确保每一步推理都有明确的逻辑依据。
03
动态规则选择
根据当前推理状态,动态选择最相关的规则进行应用,避免规则冗余和推理路径发散。
04
可解释性增强
每一步推理都伴随着明确的规则引用,使得整个推理过程透明可追溯,便于人类专家审核和调试。

实验与评估
在多个基准上的显著提升
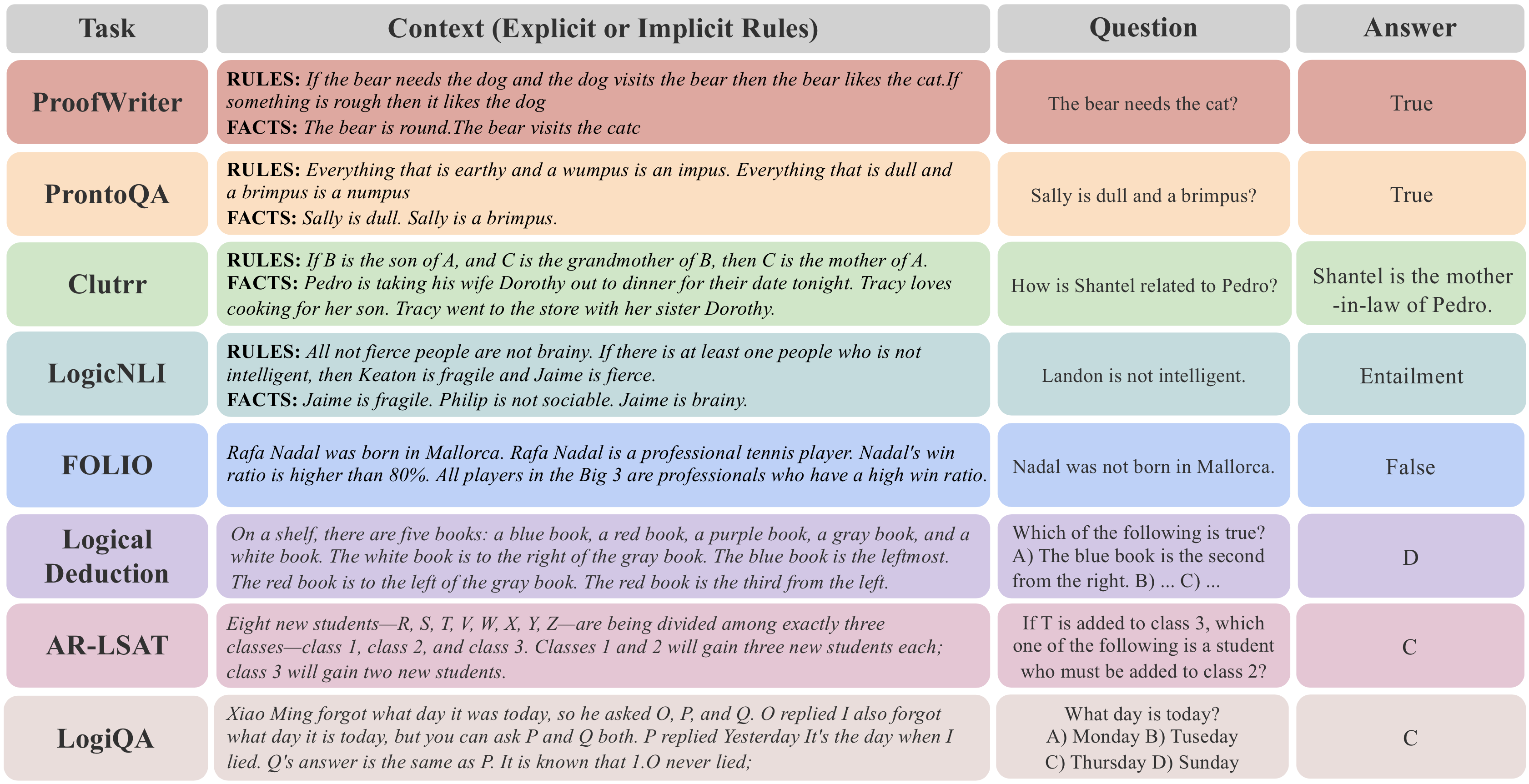
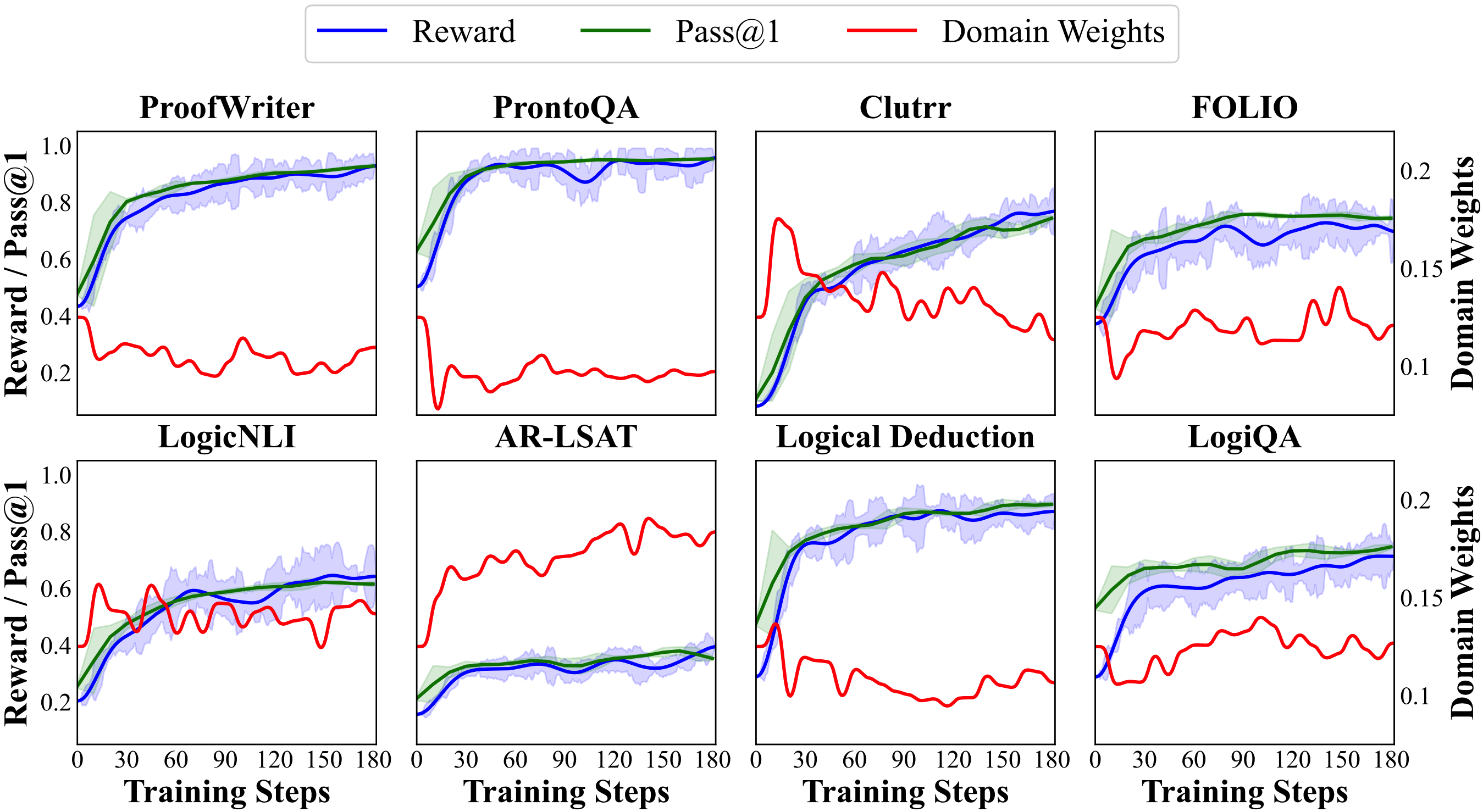
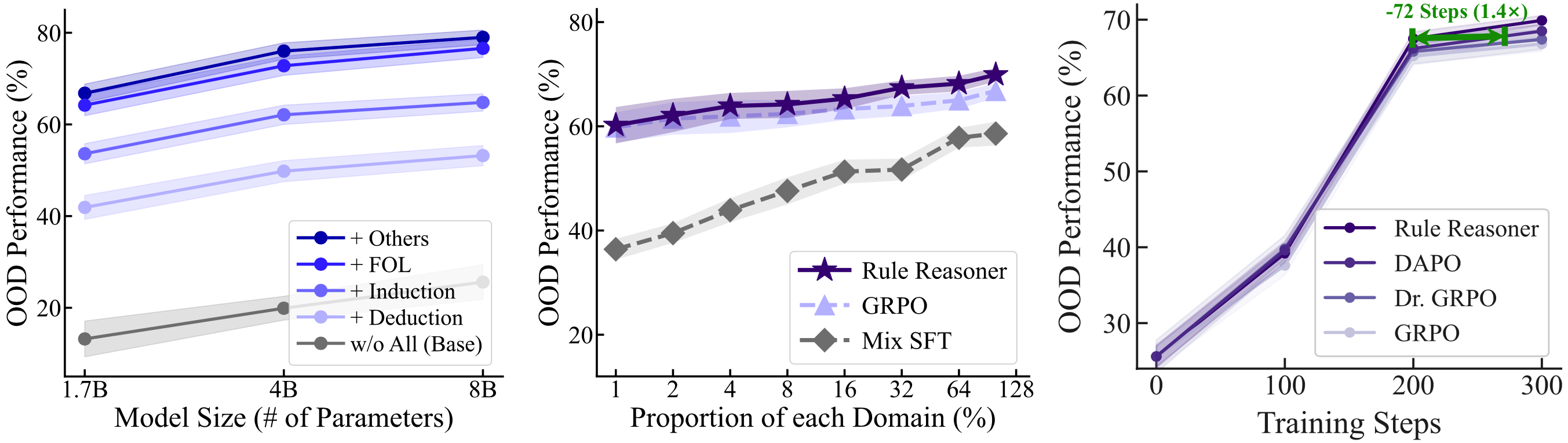
我们在多个经典逻辑推理基准上对 RuleReasoner 进行了全面评估,包括演绎推理、归纳推理和常识推理等多种任务类型。
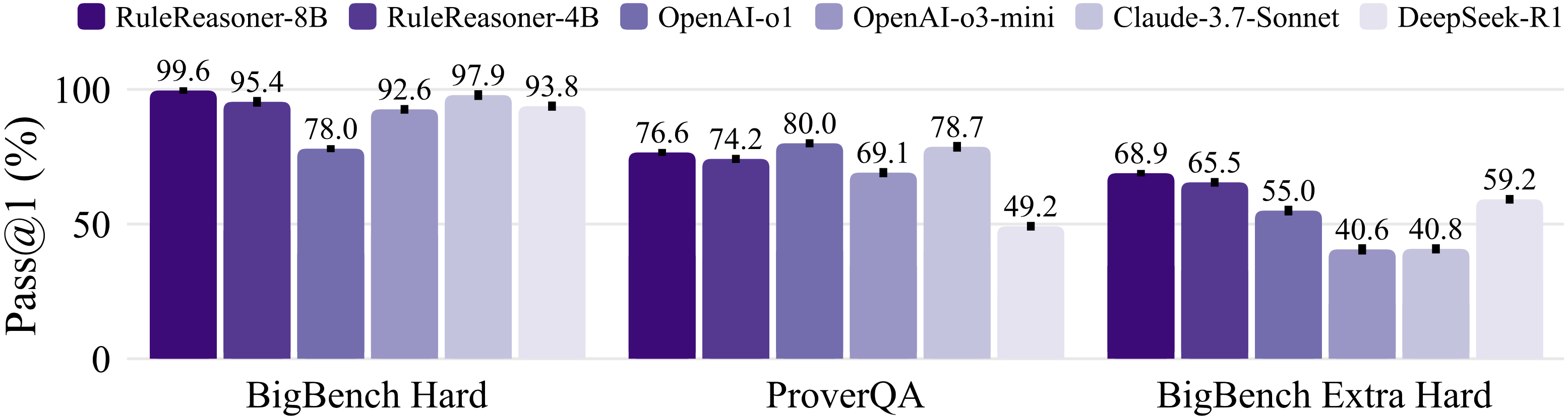
准确率显著提升
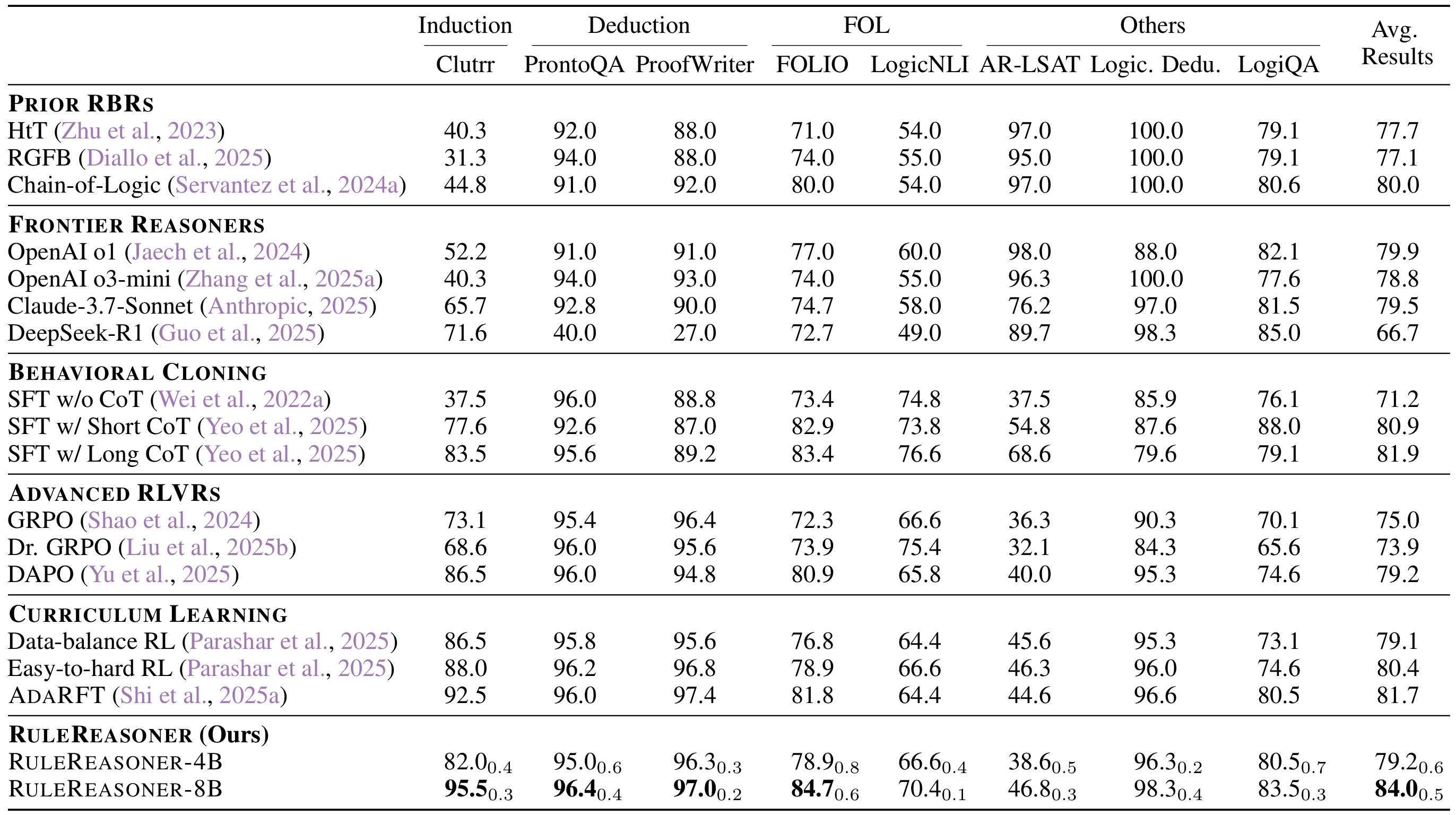
在多个逻辑推理基准上,RuleReasoner 相比基线方法平均提升了 15-25% 的准确率,特别是在需要多步推理的复杂任务中表现尤为突出。
推理过程更可解释
通过显式的规则引用,RuleReasoner 生成的推理路径更加清晰透明,人类专家可以轻松理解和验证每一步推理的合理性。
泛化能力更强
在跨领域和零样本场景下,RuleReasoner 展现出更强的泛化能力,证明了规则引导机制的通用性和鲁棒性。
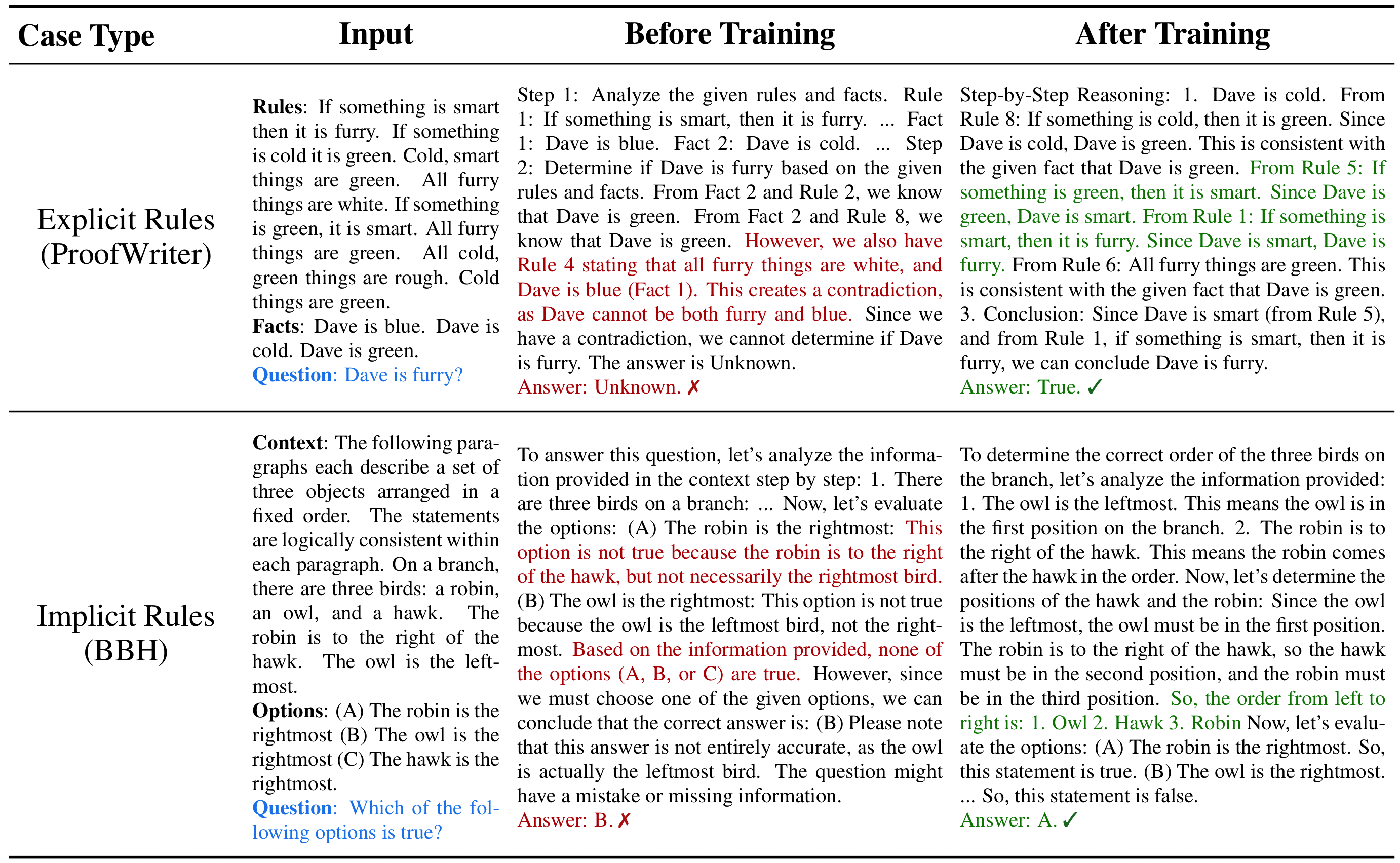
案例分析
真实推理场景中的表现
通过具体案例分析,我们可以更直观地看到 RuleReasoner 在实际推理任务中的优势。
展望
迈向更可靠的推理智能
RuleReasoner 的提出,为构建更可靠、可解释的推理系统提供了新的思路。未来,我们将继续在以下方向深入探索:
🧠
自动规则学习
让模型能够从数据中自动学习和提炼推理规则,减少人工干预。
🔄
多模态推理
将规则引导机制扩展到视觉、语音等多模态推理场景。
🤝
人机协同推理
构建人类专家与AI系统协同推理的交互框架,充分发挥各自优势。
我们相信,通过将符号推理的严谨性与神经网络的灵活性相结合,RuleReasoner 为实现真正可信赖的人工智能推理系统迈出了重要一步。
Logical ReasoningRule-based ReasoningLarge Language ModelsCurriculum Learning
Authors
Yang Liu*1, Jiaqi Li*1, Zilong Zheng1
1 BIGAI TongAgents
* Core contributors.