当 AI Agent 越来越多地承担搜索、调研、知识整合等复杂任务,一个关键瓶颈正变得越来越明显:很多问题不是"搜不到",而是"不会搜"。
对于简单查询,传统检索系统往往已经足够有效;但在更真实的 Agent 场景中,用户提出的问题常常包含隐含目标、跨步推理需求和抽象语义跳跃。此时,Agent 若只是把原始问题直接丢给检索器,往往难以找到真正有用的证据。论文《Reinforced Query Reasoners for Reasoning-intensive Retrieval Tasks》正是围绕这一问题展开:能否让一个轻量级模型先对查询进行推理和重写,再去检索,从而提升复杂检索任务的效果与部署性?
背景
对 Agent 来说,检索不只是匹配,更是理解用户真正想做什么
论文指出,传统 IR 方法擅长文本匹配与语义匹配,但在 reasoning-intensive retrieval 中表现不足。因为这类任务往往要求系统跨越"用户表面表述"和"真正相关文档"之间的推理鸿沟:相关文档未必直接包含查询中的关键词,甚至在表层语义上也并不相似。系统需要先推断用户的潜在目标,再把这个目标映射到真正相关的知识片段上。
这件事放到 Agent 上尤其重要。无论是搜索型 Agent、RAG Agent,还是 Deep Research 产品,它们都依赖一个前提:检索模块必须先把用户的问题理解到位。 一个不会"想"的搜索器,即使后面接了再强的总结、规划、写作模块,也很容易从一开始就走错方向。
换句话说,Agent 的很多失败,其实并不是发生在最终生成阶段,而是发生在第一次发出搜索请求之前。这篇论文的价值就在于,它把这个问题明确地提了出来,并给出了一条低成本、可部署的解决路径。这个 Agent 向的表述是基于论文的 retrieval setting 所做的系统层延展。
核心问题
复杂搜索的关键,不是直接搜,而是先把"隐含推理"显式化
如图1所示,用户并不是总会以"文档里的原句"来发问。很多问题需要先补出中间推理链,才能形成有效检索表达。作者将这种做法称为 query reasoning and rewriting:先由语言模型对原始 query 进行思考,生成一个带有更多推理相关内容的"reasoned query",再把这个重写后的 query 交给检索器。

如果从 Agent 角度理解,这一步其实很像一个微型的"检索前思考器":它不直接回答问题,也不直接规划完整任务,而是专门负责在检索前做一次意图展开、问题重述和证据需求显式化。
这种能力对于多跳搜索、工具调用、网页信息筛选尤其关键。因为 Agent 不是只要"搜到一些相关网页"就够了,而是要搜到对后续推理真正有用的证据。
方法
用强化学习训练小模型,让它学会写出"更会检索"的查询
现有 query reasoning 方法通常依赖 GPT-4o、Llama3-70B 这类大模型,通过 CoT prompt 直接生成 reasoned query。论文指出,这种方法虽然有效,但在真实系统中常常不现实:成本高、延迟高、部署受限,而且在很多 RAG/Agent 系统里,query reasoning 模块本身不应比主模型更大、更贵。
为此,论文提出 TongSearch QR,一个专门面向 reasoning-intensive retrieval 的小模型家族,包括 7B 和 1.5B 两个版本。其核心训练方式不是常规 SFT,而是将 query rewriting 视为强化学习问题,采用 GRPO 训练,并设计了一种新的 semi-rule-based reward。
这个 reward 的直觉非常清晰:如果模型重写后的 query,和正样本文档之间的相关性比原始 query 更高,那么这个重写就是好的。论文通过一个固定的 relevance model 来衡量这种"相关性增量",从而避免依赖昂贵的人类标注过程奖励模型,也不需要真实在线检索大语料库来计算复杂 retrieval metrics。
从 Agent 角度看,这个设计很有意义,因为它优化的不是"语言是否好看",而是这个查询是否更有利于找到真正需要的知识。这比很多仅优化生成质量的训练目标,更贴近搜索型 Agent 的真实目标。
核心发现
关键发现一:小模型也能成为高质量的"检索前推理器"
论文在 BRIGHT benchmark 上评估 TongSearch QR。如图2所示,在 BM25 检索器之上,TongSearch QR-7B 的平均 nDCG@10 达到 27.9,超过 GPT-4o 的 26.5,并接近甚至可比肩多个更大的 reasoning model;TongSearch QR-1.5B 也达到 24.6,表现出很强的轻量化潜力。
这意味着,Agent 系统不一定非要依赖昂贵大模型,才能在检索前做"像样的推理"。对于很多现实部署场景,一个专门训练过的小模型就足以承担这项工作。
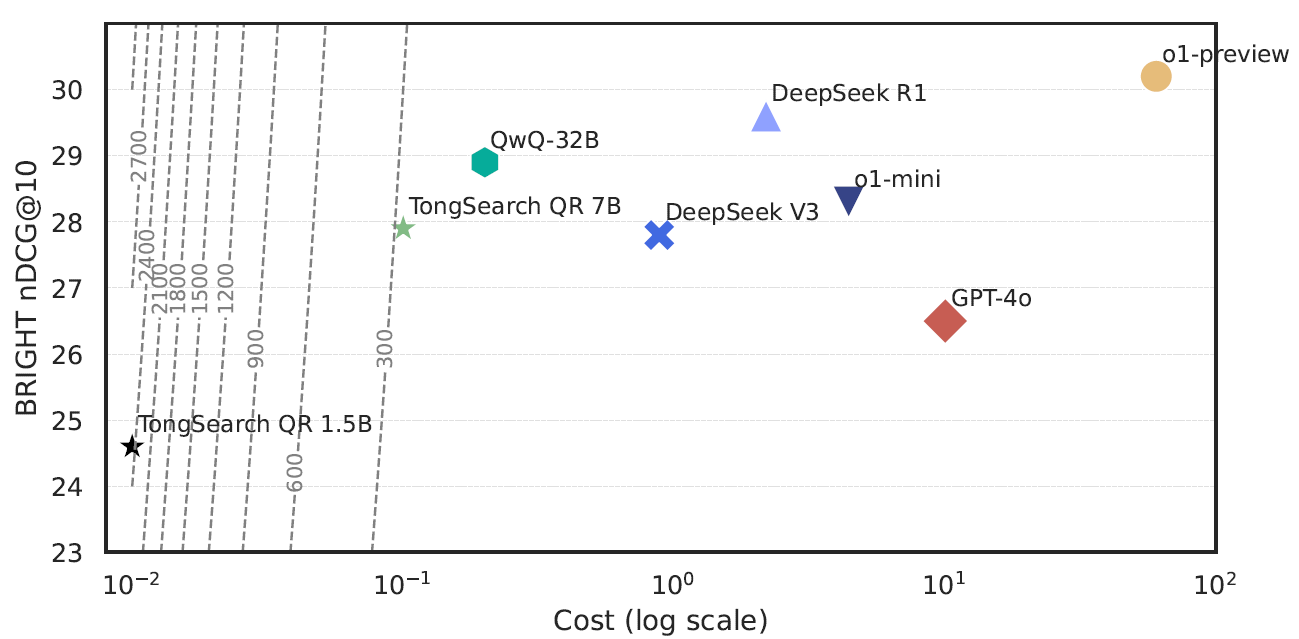
关键发现二:它特别适合预算敏感、需要规模化部署的 Agent 系统
论文进一步比较了不同模型的性能、成本与效率。按照文中的计算,TongSearch QR-7B 和 1.5B 的 efficiency 分别达到 279.0 和 2460.0,显著高于 GPT-4o、DeepSeek R1、o1-preview 等模型。尤其是 1.5B 版本,虽然绝对性能不是最高,但性价比极其突出。
这对于 Agent 落地非常关键。因为搜索型 Agent 往往要高频、多轮地发起检索请求。如果每轮都调用重型 reasoning model,系统成本会迅速失控;而轻量 query reasoner 则更适合做前置模块,嵌入到实际产品链路中。
也就是说,TongSearch QR 提供的不是"更强一点的 query rewrite 技巧",而是一个更现实的工程范式:把复杂搜索前的思考过程,交给一个便宜但专门训练过的小模型。
关键发现三:它不仅能配 BM25,也能和更强检索器协同增益
如图3所示,论文不只验证了 TongSearch QR 在 BM25 上的效果,还将它与 ReasonIR 这种专门为 reasoning-intensive retrieval 训练的检索器结合。结果显示,TongSearch QR-7B 与 ReasonIR 配合后达到 31.9 的平均 nDCG@10,高于 GPT-4 reasoned queries 配合 ReasonIR 的 29.9。
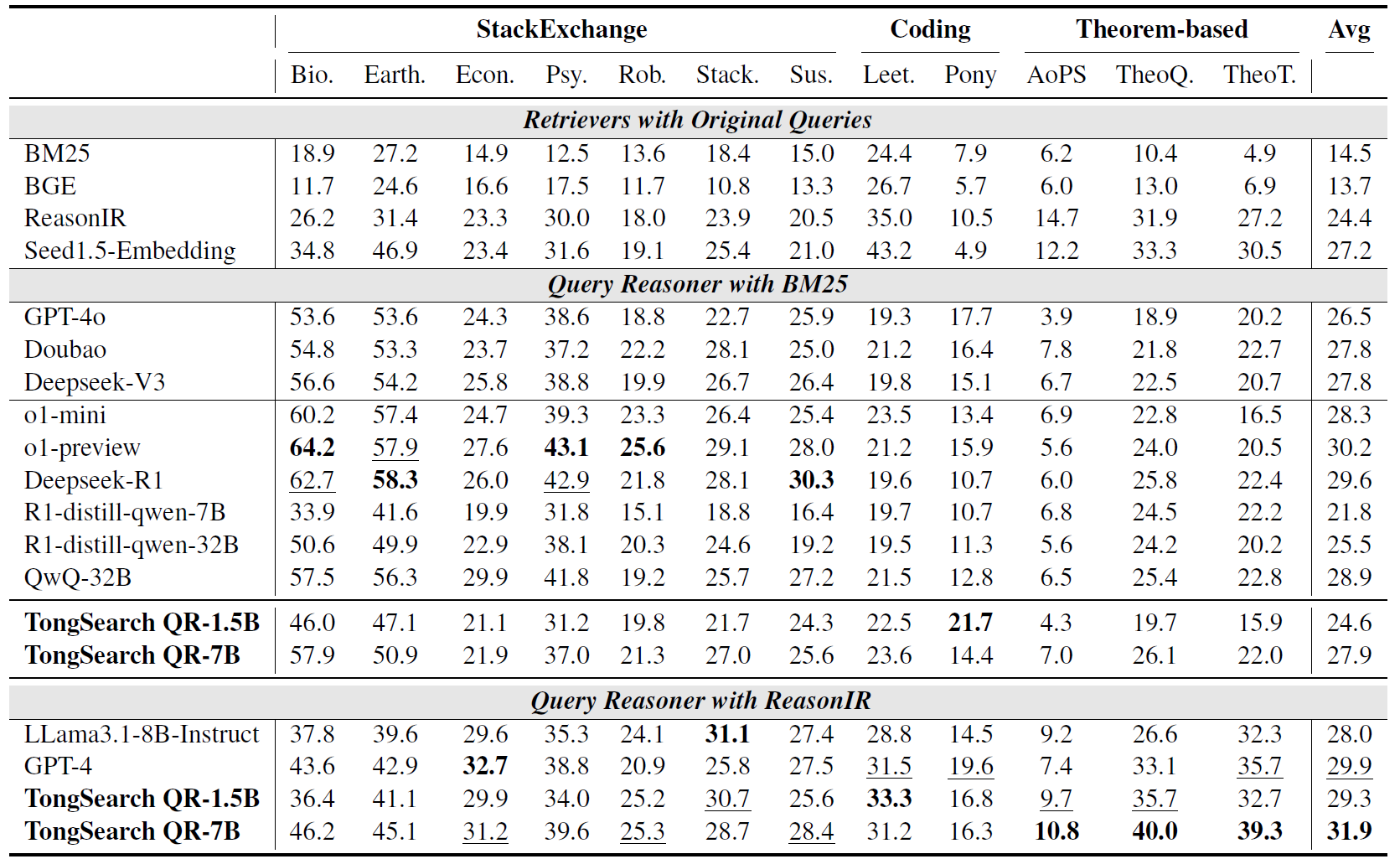
这说明 TongSearch QR 的价值不绑定于某一种后端检索器。对于 Agent 架构而言,这非常重要,因为实际系统往往会随着业务演进不断替换 retriever、reranker 或索引方式。一个独立、可迁移的 query reasoner 模块,更容易插入到不同检索栈中。
展望
从"会搜"到"会做研究":轻量推理组件会成为 Agent 基础设施吗?
论文结尾提到,TongSearch QR 有望服务于 retrieval-augmented generation pipelines 和最新的 deep research products。这个判断非常值得重视。因为随着 Agent 从单轮问答走向多步调研与任务执行,系统越来越需要一些便宜、专门、可插拔的中间能力模块,而不是把所有能力都压在一个巨型主模型上。
TongSearch QR 展示的正是这样一种方向:不是让一个模型包办一切,而是为 Agent 链路中的"检索前推理"单独打造高性价比组件。
未来,类似思路还可以继续扩展到:
- 工具调用前的参数推理
- 多轮检索中的查询演化
- Deep Research 中的子问题生成
- 面向长任务的证据需求建模
如果说传统检索器解决的是"从哪里找",那么 TongSearch QR 这类模块解决的是"到底该找什么"。而对于真正想在开放环境中工作的 Agent 来说,后者往往正是成败所在。
AI AgentsSearch AgentQuery ReasoningReinforcement LearningRetrieval-Augmented Generation
Authors
Xubo Qin1, Jun Bai1, Jiaqi Li1, Zixia Jia†1, Zilong Zheng†1
1 BIGAI TongAgents
† Corresponding authors.