在大语言模型(LLMs)的对齐过程中,离线偏好优化(如 DPO)已成为提高效率的主流。然而,现有的方法大多遵循 Bradley-Terry (BT) 模型,这在现实场景中面临三大严峻挑战:对成对数据的依赖、训练分布偏移以及人类行为的"非理性"假设。
近日,北京通用人工智能研究院 (BIGAI) 联合 中国科学技术大学 团队,在 EMNLP 2025 发表了研究:UAPO (Adaptive Preference Optimization with Uncertainty-aware Utility Anchor)。该方法通过引入"效用锚点",首次实现了对不确定偏好数据的稳健建模。
核心挑战
为什么现有偏好优化方法会"失灵"?
目前的偏好对齐方法(如 DPO, SimPO)在实际应用中遇到了瓶颈:
01
数据层面的成对约束
BT 模型强行要求"优-劣"成对数据,但在现实中,人类偏好往往是非对比性的。
02
优化层面的分布偏移
过度优化(Reward Hacking)导致模型在面对分布外(OOD)样本时产生不可靠的信号。
03
认知层面的理性假设
BT 模型假设人类是完全理性的效用最大化者,但这忽视了行为经济学中经典的"风险厌恶"和"不确定性"。
创新设计
UAPO:引入效用锚点(Utility Anchor)
UAPO 借鉴了行为经济学中的锚定效应(Anchoring Effect),引入了一个可学习的"效用锚点" $y_\bot$。
该框架具备以下核心优势:
01
解耦成对依赖
通过将目标函数拆解为单点形式,UAPO 允许模型直接从非成对数据中学习,显著提升了数据利用率。
02
感知不确定性
效用锚点能够捕捉标注过程中的模糊信号,并在理论上等同于在悲观强化学习(Pessimistic RL)中引入"不确定性惩罚",防止模型陷入奖励陷阱。
03
更平滑的训练动态
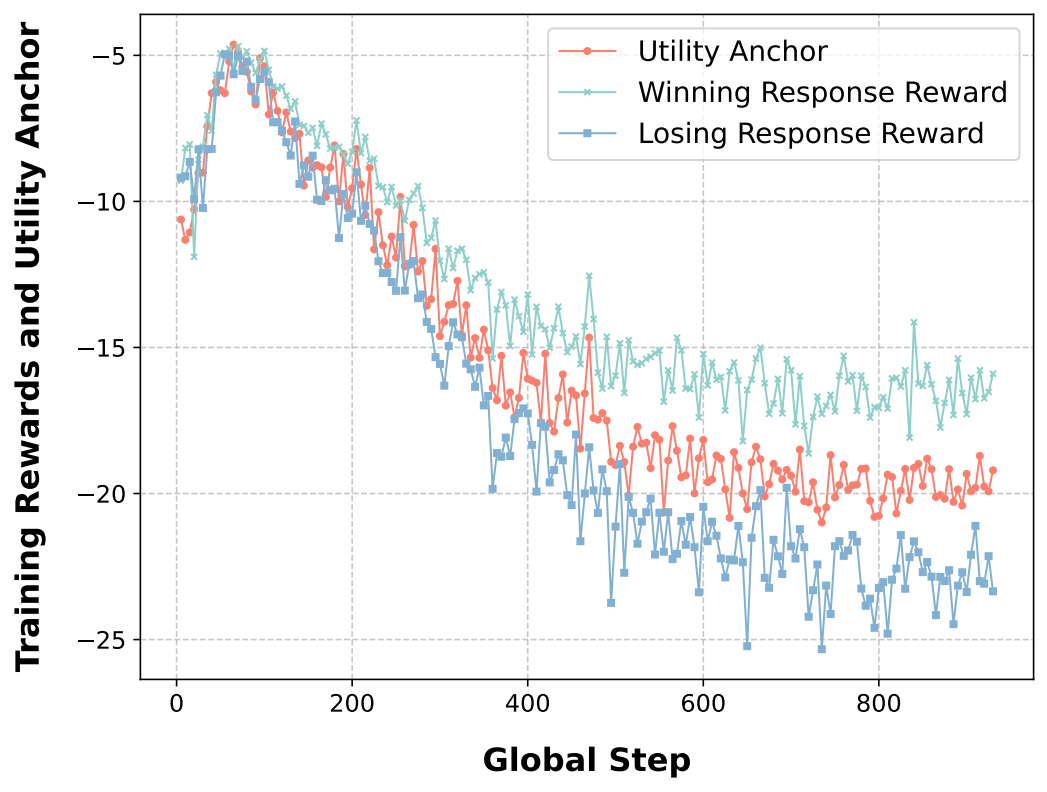
相比 DPO,UAPO 在训练过程中表现出更低且更稳定的 KL 散度,更好地保留了预训练模型的原始能力。
实验表现
卓越的泛化能力与鲁棒性
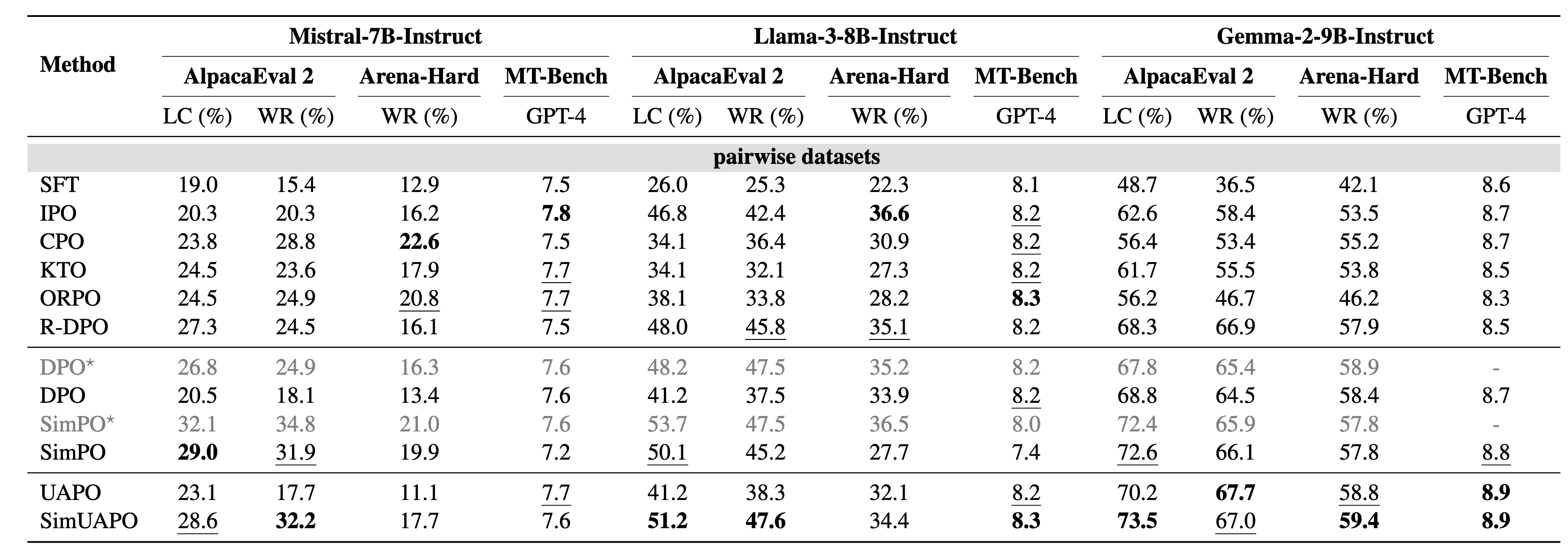
研究团队在 Mistral、Llama-3 和 Gemma-2 等多种模型上进行了广泛验证,结果表明:
基准测试领先
在 AlpacaEval 2 和 Arena-Hard 上,UAPO 变体(如 SimUAPO)一致优于原始的 SimPO 和 DPO。在 Gemma-2-9B 上,SimUAPO 达到了 73.5% 的长度控制胜率(LC)。
无惧分布偏移
在 RewardBench 2 等 OOD 基准上,UAPO 表现出更强的迁移能力,尤其是在数学推理和安全性评估方面。
抵御数据噪声
即便在 40% 的偏好标注被随机翻转(噪声污染)的极端情况下,UAPO 的性能下降也远小于传统方法。
展望
迈向可托付的对齐人工智能
UAPO 的发布不仅是算法上的优化,更是对"如何教 LLM 做出判断"的深刻洞察。对齐不应仅仅是"喂养"标准答案,更应是教会模型理解价值的尺度与不确定性的边界。
未来,团队将继续探索:
🔄
自监督对齐
利用效用锚点实现模型自我博弈与迭代。
🧩
复杂任务对齐
在长文本生成与复杂逻辑链中验证 UAPO 的有效性。
LLM 对齐偏好优化效用锚点不确定性
Authors
Xiaobo Wang1,3, Zixia Jia3, Jiaqi Li3, Qi Liu*1,2, Zilong Zheng*3
1 USTC, 2 IAI, 3 BIGAI
* 通讯作者.