RESEARCH · December 2025
Absolute Zero Reasoner: Zero-Data Reinforcement Self-Play Reasoning
Absolute Zero Reasoner enables a single model to act as both problem proposer and solver through a self-play paradigm, achieving continuous improvement in general reasoning without relying on any human data
Reinforcement Learning with Verifiable Rewards (RLVR) has demonstrated tremendous potential in enhancing the reasoning capabilities of large language models — models can learn directly from task-based outcome rewards without relying on human-annotated process supervision. However, existing RLVR methods remain tied to human-curated question-answer datasets. The scarcity of high-quality data raises a fundamental concern: the long-term scalability of human supervision is inherently limited, a bottleneck already well recognized in the language model pretraining community.
We propose a new RLVR paradigm — Absolute Zero. Under this paradigm, a single model simultaneously serves as both the problem proposer and the solver, continuously improving its reasoning through self-play, without relying on any external human data or distilled data. Building on this paradigm, we implement Absolute Zero Reasoner (AZR), a self-play reasoning system grounded in code execution environments.
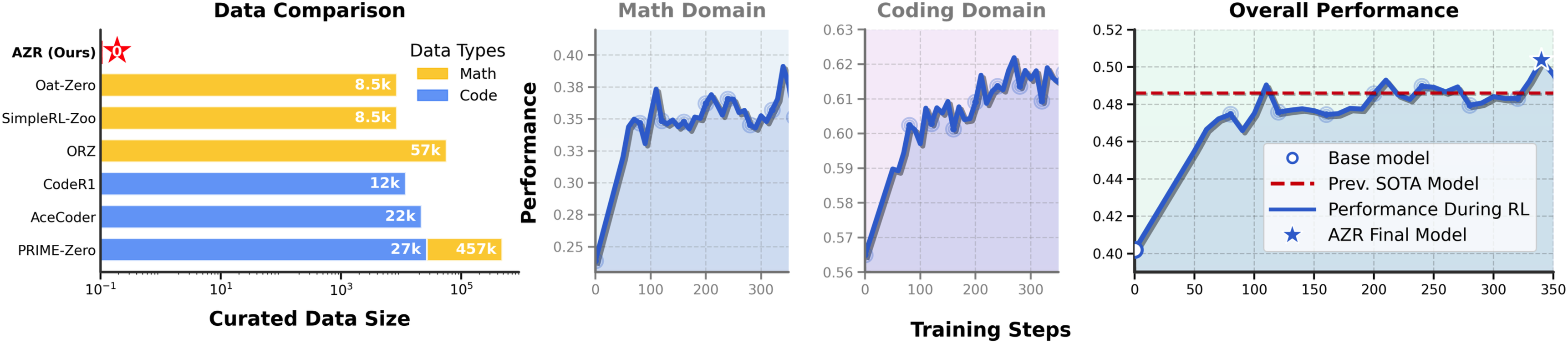
In terms of results, the most surprising aspect of AZR is that without using any human data, it surpasses models trained on tens of thousands of expert-annotated examples on coding and mathematical reasoning benchmarks, while also demonstrating strong generalization across 14 different subject areas in general reasoning tasks.
Core Method
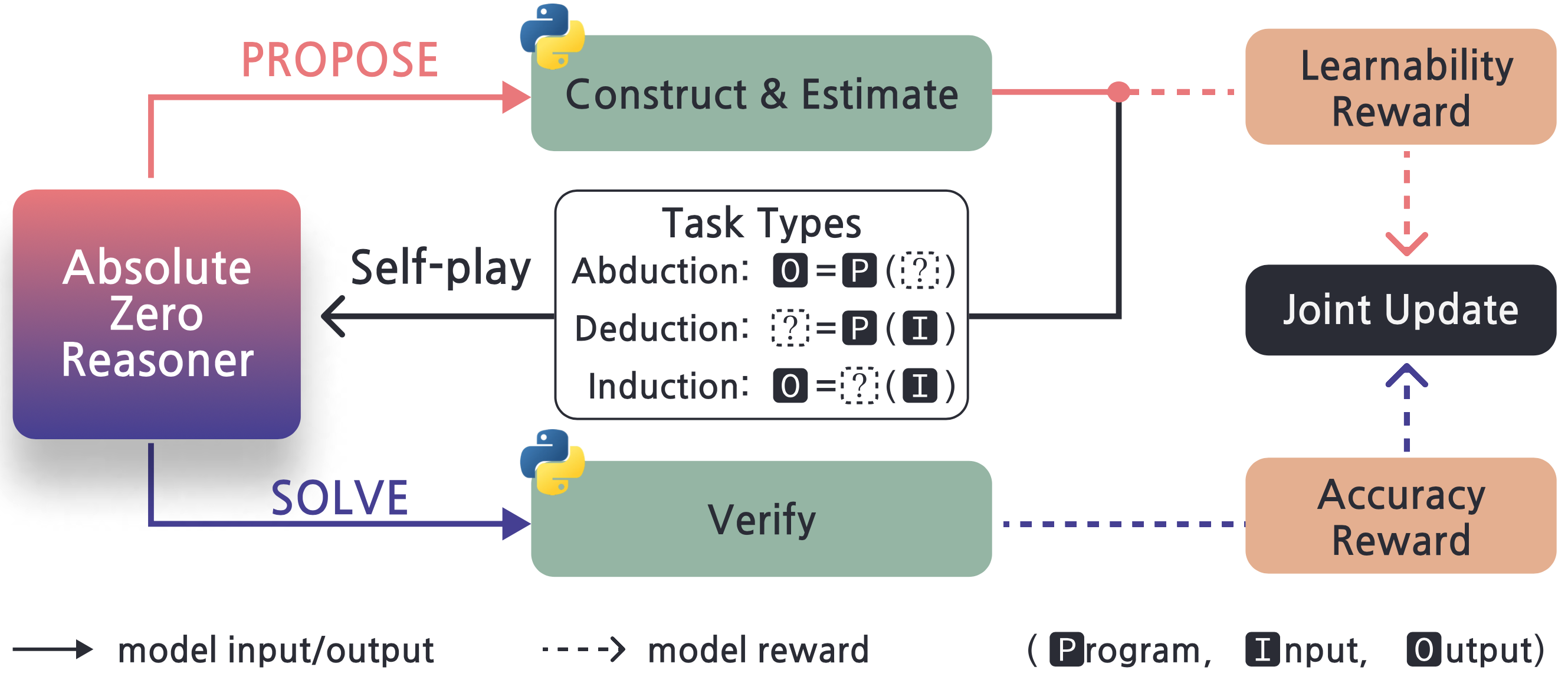
The Absolute Zero Paradigm
The core idea of Absolute Zero can be summarized in one sentence: Let the model create its own problems, solve them itself, and learn from both roles simultaneously.
Unlike traditional RLVR methods, Absolute Zero requires no pre-prepared training dataset. During training, the model plays two roles simultaneously:
- Proposer: Responsible for generating meaningful reasoning tasks. The proposer constructs challenging yet verifiable coding tasks, guided by a learnability reward — tasks that are too easy or too hard are detrimental to learning.
- Solver: Responsible for solving the tasks generated by the proposer, improving reasoning through correctness rewards.
These two roles share the same model and achieve continuous self-improvement through alternating optimization. The proposer's reward function is particularly noteworthy: it is designed around learnability, encouraging the generation of tasks that the solver "occasionally gets right" — these tasks provide the strongest learning signal.
Three Types of Reasoning Tasks
AZR leverages the code execution environment as a reliable verification tool and designs three distinct types of reasoning tasks:
- Deduction: Given a program and input, predict the output. The model needs to mentally "execute" the code logic, exercising forward reasoning.
- Abduction: Given a program and output, infer the input. The model needs to reason backward, deducing causes from results.
- Induction: Given input-output pairs, infer the program itself. The model needs to generalize from specific examples to derive general rules.
These three task types complement each other, collectively covering different dimensions of reasoning ability. Python is used as the verification environment — code generated by the proposer is actually executed to verify its validity, and the solver's answers are also checked for correctness through code execution.
Training Pipeline
The AZR training pipeline includes the following steps in each iteration:
- Propose Phase: The model generates new tasks for each task triplet in the buffer, computing learnability rewards.
- Filter Phase: Python is used to filter and validate generated tasks, ensuring they are correctly formatted and executable.
- Solve Phase: The model attempts to solve the filtered tasks, verifying answer correctness through code execution.
- Update Phase: Model parameters are jointly updated based on reward signals from both the proposer and solver.
The entire process is fully automated, requiring no human intervention or external data.
Key Findings
Zero Data Can Surpass Supervised Training
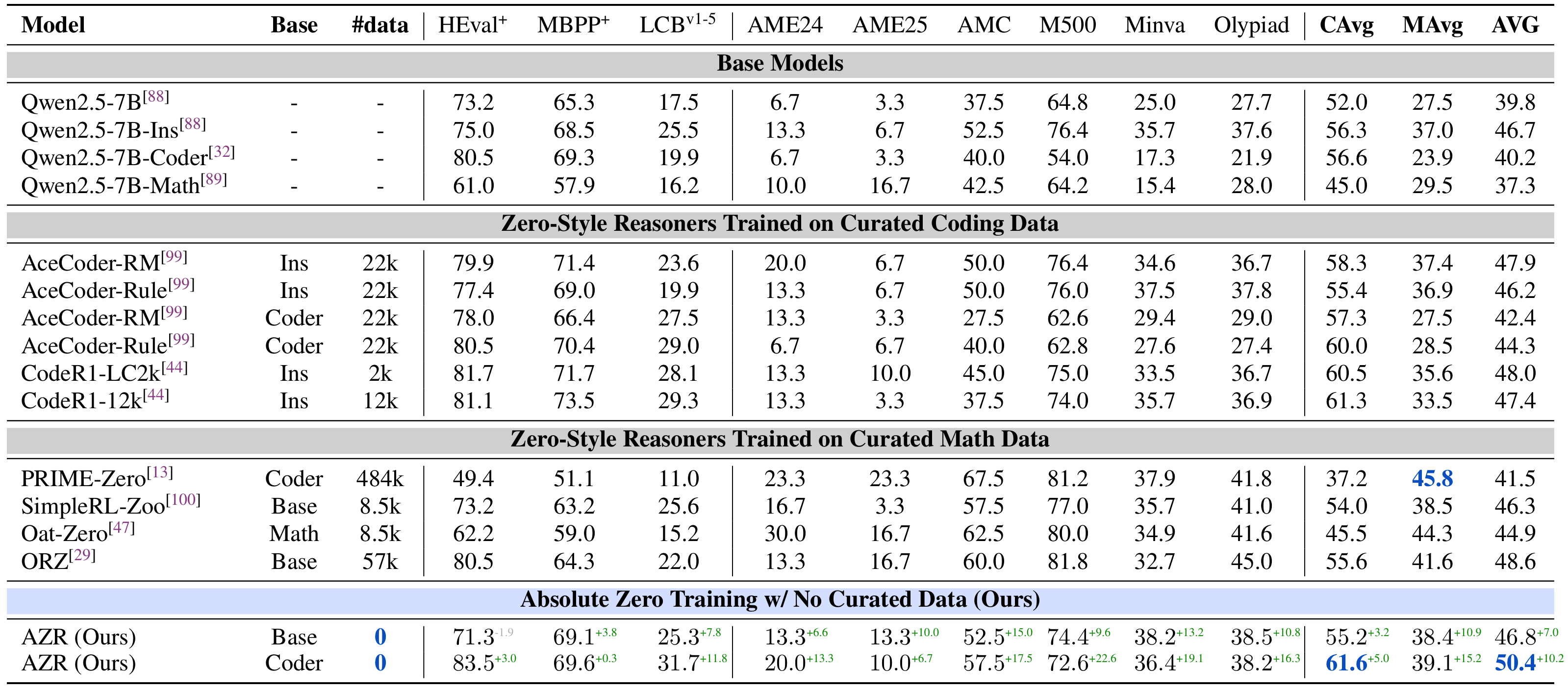
The most striking finding of AZR is that a model trained without any human data surpasses models trained on large amounts of expert-annotated data across multiple benchmarks.
On coding tasks, AZR Base and Coder achieve 10.9% and 15.2% performance improvements on in-distribution (ID) and out-of-distribution (OOD) settings respectively. On mathematical reasoning tasks, AZR models improve by 3.2% and 5.0% respectively. More notably, AZR achieved state-of-the-art performance in the coding domain at the time, surpassing models specifically trained with code data via RLVR.
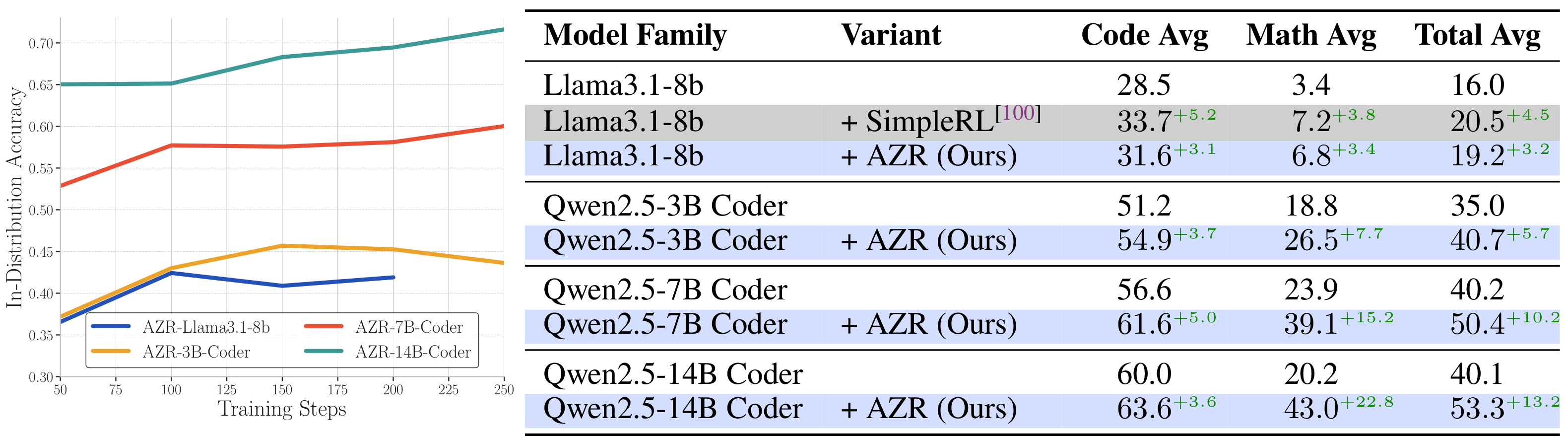
Pass@k Results: Scaling Potential
The paper also evaluates AZR's performance under the Pass@k setting. As k increases from 1 to 512, AZR demonstrates continuous performance improvement, indicating strong diversity and coverage capabilities. This property means AZR can further boost performance through inference-time scaling methods such as best-of-N sampling.

Emergence of General Reasoning Ability
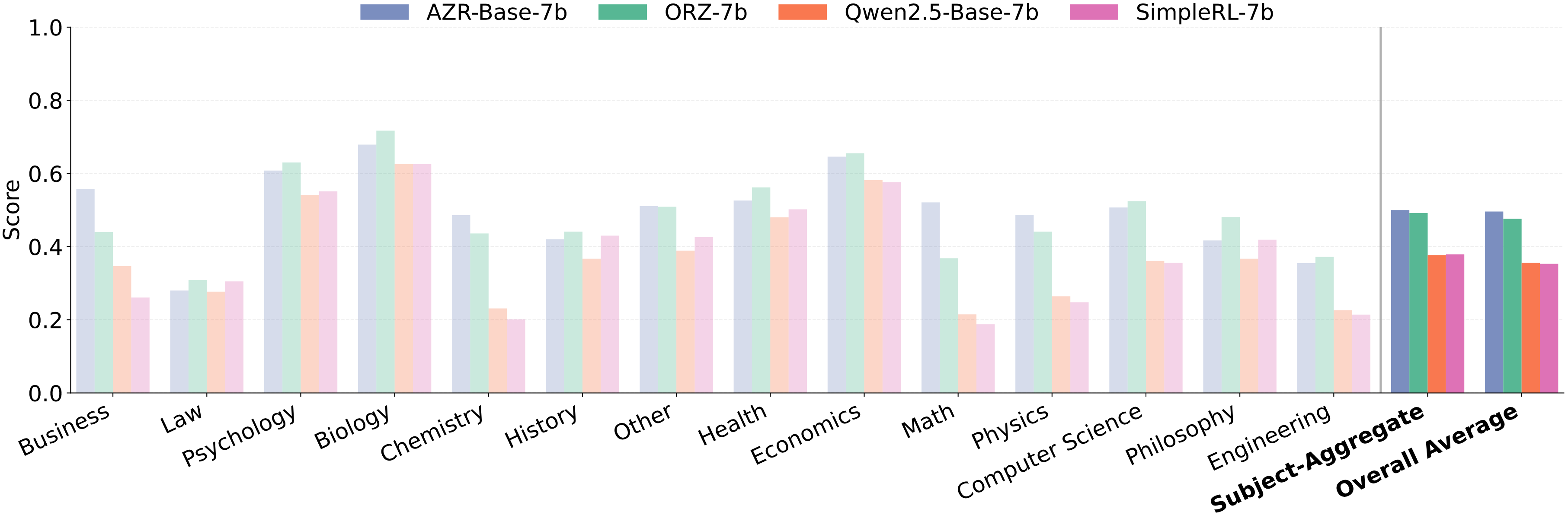
Perhaps most surprising is that although AZR's training environment involves only code tasks, it also shows significant improvements on general reasoning benchmarks. Across 14 different subject areas, AZR Base-7B outperforms the baseline model on all subjects and samples, demonstrating that the reasoning abilities acquired through code self-play exhibit strong cross-domain transferability.
Outlook
The True Significance of This Work
Looking beyond the numbers, AZR is more than a paper about "training a strong reasoning model without data." At a deeper level, it explores a fundamental question: Can AI systems achieve autonomous capability improvement through environmental interaction, entirely without human supervision?
AZR provides an encouraging preliminary answer. It demonstrates that code execution environments can serve as rich, self-verifying learning arenas where models can autonomously discover problems, solve them, and learn from the process. This "self-curriculum learning" paradigm shares deep similarities with AlphaZero's self-play in board games — both achieve capabilities beyond human data through self-play in a verifiable environment.
Of course, there are many directions for future exploration. AZR has primarily been validated in code environments — can it be extended to other types of verifiable environments (such as formal mathematics, scientific simulations)? Can the self-play dynamics be further optimized to create a more efficient "arms race" between the proposer and solver? These are all questions worth investigating.
At the very least, this paper has demonstrated one key point: When it comes to training reasoning capabilities, human data is not a necessity. A well-designed self-play system can start from zero and go further than methods that rely on human data.
This perhaps signals an important shift in the AI reasoning training paradigm — from "collecting more data" to "designing better learning environments."
LLMReasoningReinforcement LearningSelf-playZero Data
Authors
Andrew Zhao, Yiran Wu, Yang Yue, Tong Wu, Quentin Xu, Matthew Lin, Shenzhi Wang, Qingyun Wu, Zilong Zheng, Gao Huang
Tsinghua University, BIGAI, Penn State University