RESEARCH · March 2026
$OneMillion-Bench: Defining the Onboarding Standard for "Industry Digital Workers"
The TongAgents team releases $OneMillion-Bench, a high-production-value industry agent benchmark that redefines "deliverable" intelligence
As AI agents gradually transition from concept to real-world deployment, a pressing question emerges: To what extent can AI undertake high-value professional work in the real world? And can the "deliverable value" it creates be objectively measured?
Recently, the TongAgents team at the Beijing Institute for General Artificial Intelligence (BIGAI), in collaboration with Humanlaya, Sequoia China's xbench evaluation team, and M-A-P, released a groundbreaking evaluation benchmark — $OneMillion-Bench.
$OneMillion-Bench establishes a benchmark that simultaneously achieves high economic value × high discriminability × automated evaluation. It comprises 400 challenging tasks (200 in English + 200 in Chinese) spanning 92 tertiary domains across five major sectors: Finance, Law, Healthcare, Natural Sciences, and Industry. For the first time, this benchmark uses "the time and cost of human experts" as its yardstick, quantitatively assessing the economic value that AI agents can reliably deliver in real-world industry scenarios.
Background
From "Question-Answering Machines" to "Productive Workforce": Why Industry Needs a New Yardstick
As agent technology enters its "year of deployment," AI is evolving from traditional question-answering and content generation toward becoming a "digital workforce" capable of handling complex workflows. However, the field has long lacked an evaluation framework that effectively measures an agent's ability to create economic value in real business contexts — existing benchmarks predominantly focus on closed-ended tasks testing knowledge recall, with notable limitations in discriminability, automated evaluation, and especially the fidelity of real-world business scenario reproduction.
$OneMillion-Bench is a critical extension of industrial practice: we focus not only on what a model "knows," but on whether it can plan, reason, make decisions, and deliver actionable outcomes in real, open-ended, high-value professional tasks — just as a human expert would.
Design Philosophy
Where Does the Million-Dollar Value Come From? Building a Value Metric for the Real World
The core design philosophy of $OneMillion-Bench is straightforward yet profound: measure the economic value of agents in monetary terms.
We collaborated with over 100 senior experts from institutions including Morgan Stanley, Skadden Arps, Peking Union Medical College Hospital, State Grid Corporation, and Tsinghua University, investing more than 2,000 hours to jointly construct 400 highly challenging open-ended tasks across five core domains. Each task corresponds to a real expert-level work scenario.
The economic value of each task is determined by the expert time required to complete it × the authoritative market hourly rate (sourced from official statistics and the latest industry reports in both China and the United States). The cumulative economic value of all tasks exceeds one million US dollars, meaning that completing this entire benchmark in the real world would require paying expert fees on the order of one million dollars.
Core Design
Four Key Design Principles
01
High-Fidelity, High-Value Tasks
Evaluation tasks are drawn from the real workflows of practitioners with 5–15 years of experience. Each task is decomposed into 15–35 fine-grained evaluation criteria (over 7,000 in total), focusing on expert-level decision-making and hands-on competence in specific scenarios rather than superficial knowledge recall.
02
Asymmetric Penalty Mechanism to Prevent 'Superficial Correctness'
To prevent AI from inflating scores by padding content, we pioneered an evaluation scheme that incorporates penalty deductions. Critical errors or logical flaws incur heavier penalties (e.g., −20 points), guiding models toward producing rigorous, precise, and reliable outputs.
03
Deep Integration of Domestic and International Industry Scenarios
The benchmark includes independent Chinese (CN) and English (Global) subsets covering 92 tertiary industry categories, faithfully reproducing local regulations, processes, and business contexts to precisely measure region-specific professional competence.
04
Expert-Grade Industrialized Production Pipeline
Rigorous expert selection (acceptance rate <5%) combined with multi-person collaboration, adversarial review, and arbitration-based quality control ensures data quality — the final quality control pass rate for tasks is only 38.1%, guaranteeing high difficulty and high fidelity from the ground up.
Key Findings
AI Can Already Create Substantial Value, but "Reliable Delivery" Remains the Next Frontier
Based on the $OneMillion-Bench evaluation results, we have derived clear insights into the current capability boundaries of AI agents:
Significant Value Creation Capability
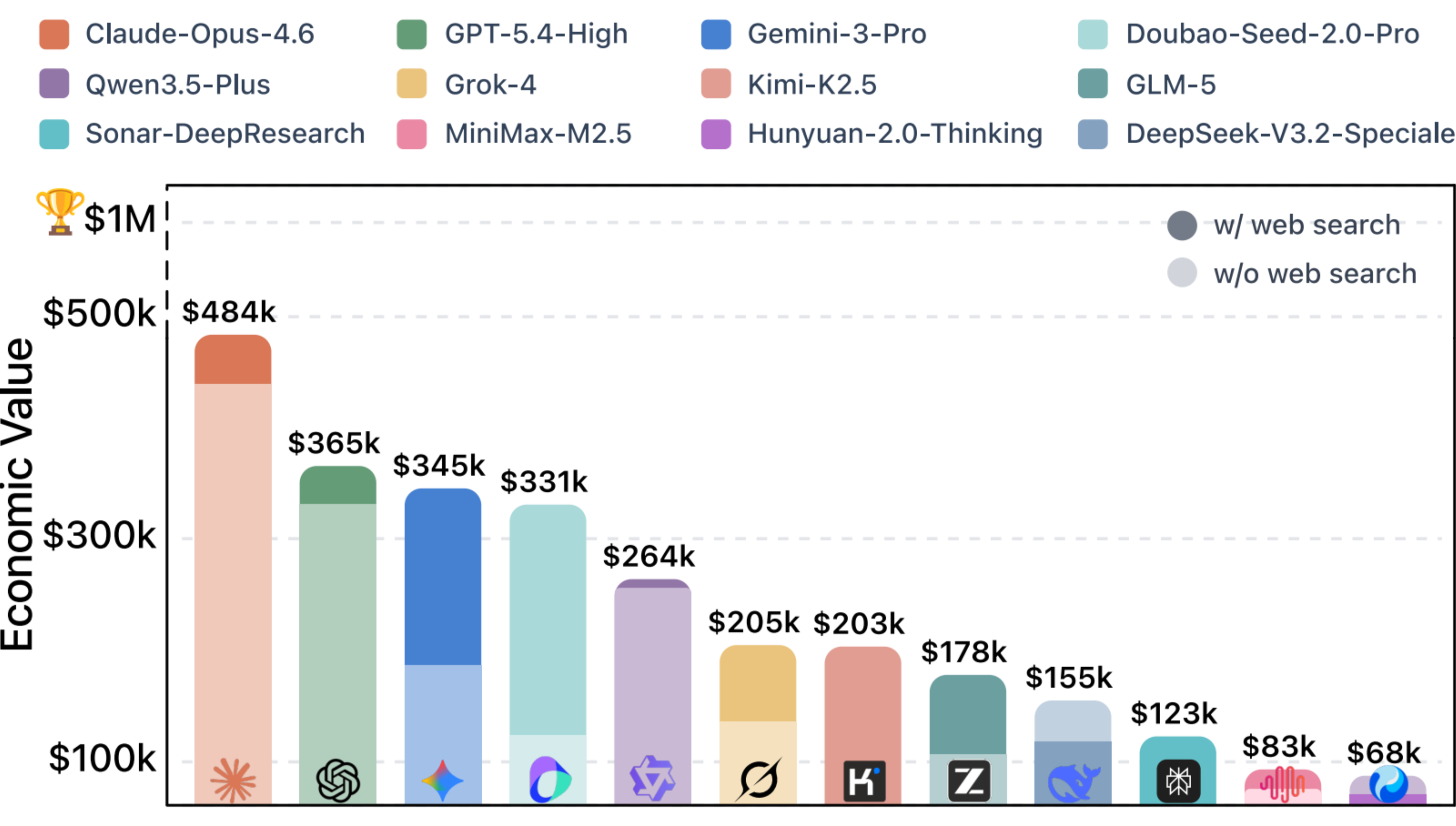
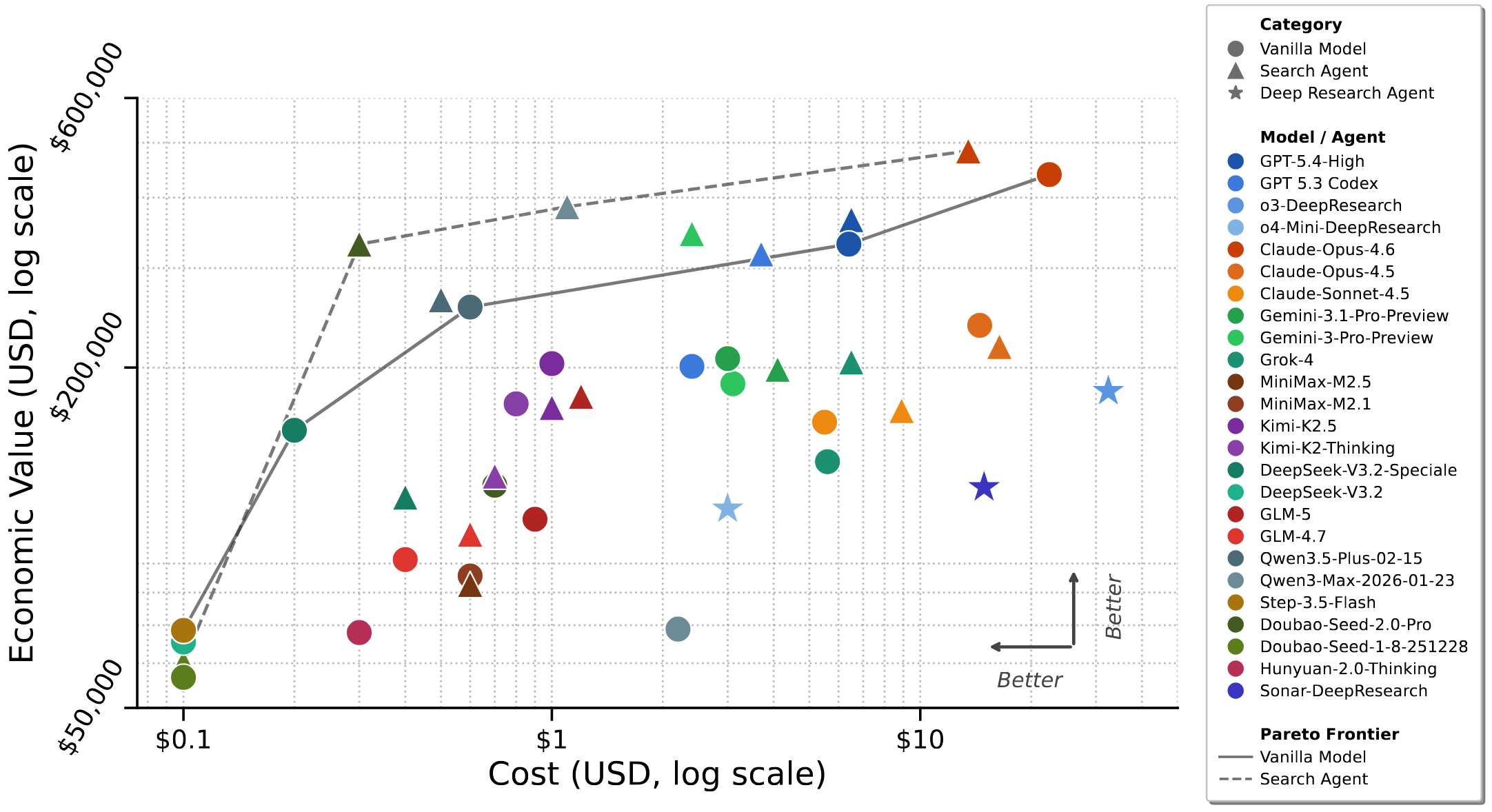
Current state-of-the-art models can generate approximately $480,000 in economic value on this benchmark, while the API costs for model invocations to complete these tasks amount to only about $100. This demonstrates that AI already possesses formidable value-creation potential for high-unit-price professional tasks.
'Pass Rate' Reveals the Delivery Gap
Although leading models achieve average scores above the "passing" threshold (>60%), when measured by a stricter pass-rate criterion (a per-task score ≥70% is considered deliverable), even the best-performing model can reliably deliver only about 45% of tasks. While AI can already "assist," a significant gap remains before it can fully and independently complete complex workflows in a trustworthy manner.
Complex Reasoning and Granular Detail Are Common Bottlenecks
Models still tend to exhibit logical shortcuts or produce overly generic responses in tasks requiring multi-step deep deduction, exploratory problem-solving, or highly actionable detail. This is precisely the core challenge that TongAgents is committed to addressing through explainable and trustworthy decision-making.
Outlook
Toward "Deliverable Artificial Intelligence"
The release of $OneMillion-Bench is more than just a leaderboard. It represents an important convergence of cutting-edge fundamental research and critical industrial needs, providing a clear direction and a rigorous litmus test for the development and optimization of industry agent frameworks. Going forward, industry agents will continue to focus on:
🧠
Deep Reasoning and Planning
Enabling agents not only to "answer correctly" but to "think thoroughly."
🏭
Reliable Deployment
Ensuring high-certainty outputs in real-world, dynamic business environments.
🤝
Human-AI Collaboration
Making agents trustworthy, practical, and collaborative "professional partners" for human experts.
Standing at the tipping point of an explosion in agent technology, we invite colleagues from both academia and industry to engage with, adopt, and help refine this benchmark. Together, let us drive AI agents across the critical threshold from "demo-ready" to "delivery-ready," ensuring that every increment of intelligence translates into real productive force that advances industry.
AI AgentsBenchmarkingEconomic Value$OneMillion-Bench
Authors
Qianyu Yang*1, Yang Liu*2, Jiaqi Li*2, Jun Bai*2, Hao Chen2, Kaiyuan Chen3, Tiliang Duan1, Jiayun Dong1, Xiaobo Hu3, Zixia Jia2, Yang Liu3, Tao Peng1, Yixin Ren3, Ran Tian1, Zaiyuan Wang1, Yanglihong Xiao1, Gang Yao2, Lingyue Yin1, Ge Zhang4, Chun Zhang1, Jianpeng Jiao†1, Zilong Zheng†2, Yuan Gong†3
1 Humanlaya, 2 BIGAI TongAgents, 3 xbench, 4 M-A-P
* Core contributors. † Corresponding authors.